Förderjahr 2024 / Stipendium Call #19 / ProjektID: 7335 / Projekt: Building Knowledge Graphs for Under Resourced Languages
Have you ever thought about how much of the Web is in just a few languages, like English or Spanish? It's a bit like having a meeting where only some people can join in the conversation! This is a real issue for Under-Resourced Languages speakers.
What are Knowledge Graphs, and why should we care?
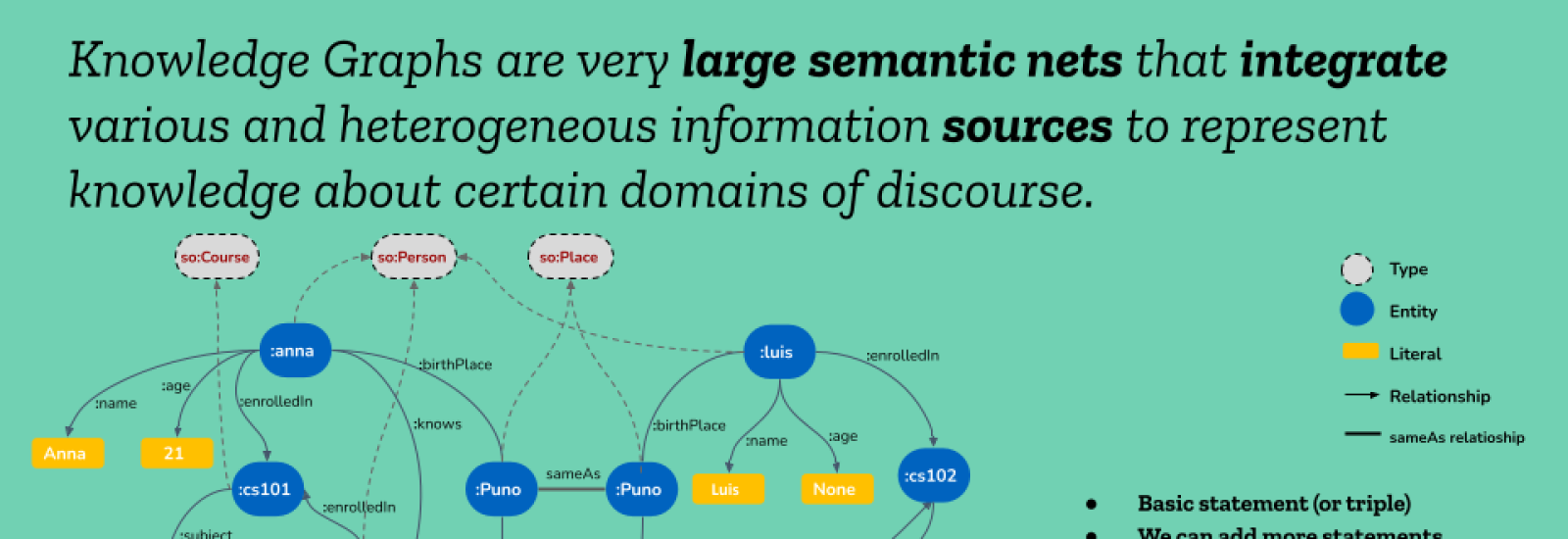
Think of Knowledge Graphs (KGs) as giant, interconnected maps of information. They help power a lot of the things we use every day, like search engines, question answering systems, and voice assistants. Big companies like Amazon, Google, and Microsoft have been building these knowledge graphs mostly in English, Spanish, and a few other common languages. That's great for some languages and communities, but what about the rest of the world? Which contains about 7000 languages.

The problem: Bias in the digital world
The data used to build these knowledge graphs often comes from the web, which means it is biased. Some languages, viewpoints, and topics get over-represented, while others, especially those belonging to Under-Represented Communities (URCs), are left out because they do not have a presence on the Web. This can lead to the perpetuation of those biases, while developing AI applications and services, based on the Web data. In consequence, the AI applications might not accurately reflect the knowledge of the world.
How can we be more inclusive?
Knowledge graphs can be amazing tools for including everyone, and for representing multilingual data. To make this happen, we need to focus on creating community-centred and language-aligned knowledge graphs. This means being more inclusive about how we collect, model, process, and share data from under-resourced communities.
- Promote transparency and equity in knowledge graph construction: Current knowledge graph construction methods lack transparency and equity, particularly regarding the knowledge and data of under-resourced languages.
- Adopt a community-driven approach: When building knowledge graphs for under-resourced languages, it is crucial to involve the communities that speak those languages. This can ensure that the knowledge graphs are accurate, relevant, and meet the needs of the community.
- Empower under-represented communities: By involving under-r represented communities in the development of knowledge graphs, these communities can be empowered to contribute their knowledge and viewpoints to AI applications, ensuring their voices are heard and represented.
- Crosslinguistic awareness: It's important to understand how different languages interact in the minds of people who speak multiple languages, particularly when one of those is an under-resourced language. It’s like trying to see the world through their eyes.
- Support the development of resources for under-resourced languages: Under-resourced languages often lack the necessary resources such as data, text, and media, which hinders their ability to be included in technology. To be more inclusive, it is crucial to support the development of these resources, which can then be used to build knowledge graphs.
The future is community-centred and language-aligned!
We need to make sure that technology benefits everyone, not just those who speak the most common languages. It is time to build digital tools and spaces that are truly inclusive and representative of all the world's languages. By prioritising inclusivity, we can move towards a more equitable and richer digital world for everyone!
