
Förderjahr 2020 / Stipendien Call #15 / ProjektID: 5237 / Projekt: Container scheduling using ML-based workload characterization for heterogeneous computer clusters
The emerging Edge Computing paradigm promises the much needed compute power at the origin of our data. But how can we conduct research with defacto no large-scale public Edge infrastructure? Insights from simulation-based research.
The vision
The Edge Computing paradigm promises to make "sci-fi" sounding applications reality and allows developers to analyze and process data at their origin - the Edge. Applications that may become reality by embracing this paradigm ranges from video analytics [1], cognitive AR [2], context-aware AI [3] and autonomous driving [4] - making our cities smarter.
By deploying different types of nodes throughout our cities, we can develop a computing fabric, which can act on the data produced and enables developers to successfully run aforementioned programs.
The problem arises through the high heterogeneity of devices. In Chicago a program to develop nodes that are able to sense their environment have different types of computing resources equipped [5]. Nvidia is pushing new embedded GPU hardware for Edge Computing scenarios [6]. Google produces so-called EdgeTPU boards that deliver very fast inference times [7].
This diverse range of compute nodes manifests in a highly variant performance across different programs, which makes it important to decide in an intelligent-manner where to start each program.
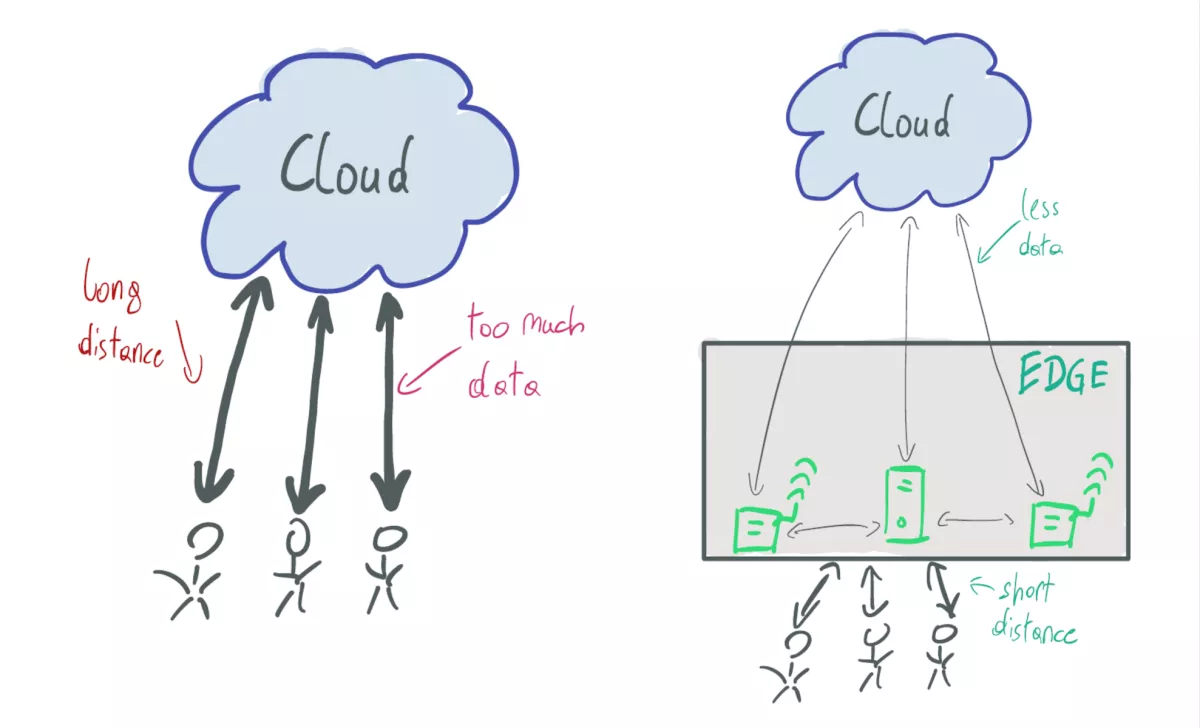
The figure shows on the left the current cloud-centric architcture, where users have to interact with the cloud to process their data, while on th left edge devices are placed in near proximity to users. Advantages of such a system are the possibility to preprocess/filter data at the origin and to host applications close to users to guarantee short response times.
The problem
Sadly it is hard to evaluate strategies concerning Edge computing infrastructures. Rausch et al. [8] accredit this to two reasons:
- the complexity and heterogeneity (as outlined before)
- missing reference architectures of edge infrastructures, standardized benchmarks and data on real-world deployments
As already highlighted in the previous section, we face an unseen range of devices that should interact together, giving developers the possibility for on-device processing and should lift them from the burden of managing their applications.
The second point is concerned with the fact that this paradigm is novel and no public infrastructures are deployed, nor has there been much research for providing standardized benchmarks with which one could evaluate solutions.
The problem in summary: we lack the possibility of deploying and testing large-scale infrastructures - knowledge inherent to real life experiences.
My solution & a glimpse into ongoing research
To evaluate my final solution, I am grateful to write my thesis at the Distributed Systems Group (TU Wien), as they provide me with the necessary tools and knowledge. I overcome the problem at hand by combining the following components:
- access to modern Edge devices
- skippy: scheduler targeted at Serverless Edge Functions
- faas-sim - simulator for Serverless Edge Computing scenarios
- ether: a tool to synthesize edge topologies
All three tools are part of the Edge Run project that offers developers the necessary tools for evaluating Edge scenarios.
So how do I use these tools?
For my thesis it is important to simulate the behavior of Edge topologies and the deployed applications, focusing on the aspect of app placement. Put simply: the decision on which computer a program should run.
A simplified look into my evaluation:
- Find a use-case: Smart City
- Develop apps: i.e.: AI-based Object Detection and Speech-to-text inference
- Evaluate the baseline performance of each app on each device
- Feed the simulator with the response times measured in the previous step
- Generate a plausible topology using ether
- Create request patterns that simulate the users
- Execute faas-sim and interpret the results
- The results contain defacto all events that happen during a simulation.
- Examles for such events:
- Function executions
- App placements (scheduling)
- Network traffic
- Scaling decisions
- Examles for such events:
These steps make it possible to get a glimpse of how the system in real life could work and allows me to solve the placement problem by evaluating and comparing different techniques.
[1] Satyanarayanan, Mahadev, et al. "Edge analytics in the internet of things." IEEE Pervasive Computing 14.2 (2015): 24-31.
[2] Satyanarayanan, Mahadev, and Nigel Davies. "Augmenting cognition through edge computing." Computer 52.7 (2019): 37-46.
[3] Rausch, Thomas, and Schahram Dustdar. "Edge intelligence: The convergence of humans, things, and ai." 2019 IEEE International Conference on Cloud Engineering (IC2E). IEEE, 2019.
[4] Tareq, Md Mostofa Kamal, et al. "Ultra reliable, low latency vehicle-to-infrastructure wireless communications with edge computing." 2018 IEEE Global Communications Conference (GLOBECOM). IEEE, 2018.
[5] https://arrayofthings.github.io/
[6] https://www.nvidia.com/en-gb/autonomous-machines/embedded-systems/jetso…
[7] https://coral.ai/about-coral/
[8] Rausch, Thomas, et al. "Synthesizing Plausible Infrastructure Configurations for Evaluating Edge Computing Systems." 3rd {USENIX} Workshop on Hot Topics in Edge Computing (HotEdge 20). 2020.

