
Förderjahr 2017 / Stipendien Call #12 / ProjektID: 2418 / Projekt: Decentralised Data Provenance based on the Blockchain
Before we can see how the blockchain can help data provenance we have to understand what the blockchain is in the first place. The blockchain itself can be very simplified described as a distributed ledger. Now the important part about this is the distribution. There is not one single place which can tell what is written in this ledger but many participants all around the globe must have a consensus about what is written in the blockchain. This fact makes it extremely difficult, practically impossible, to change data once written on the blockchain. But the blockchain is not some simple innovation which functions without constraints. It is a necessity for cryptocurrencies like Bitcoin and works only as a result of a complicated mixture of socioeconomic and technical factors which are out of the scope of this blog entry. To put it short, it is doubtful that the blockchain can work without an economic incentive like the one provided by cryptocurrencies.
To get a little bit more technical every new information that someone wants to write to this ledger has to be collected by participants of the network into so called blocks which may contain information from different users. This is still a very high-level view of everything without any details about the internals of a block. To be accepted as a valid block on the blockchain, this new block has to reference an older block and per definition, it always has to references the newest existing block on the longest chain. The last step is to announce this new block to everyone else in the network. Once accepted by more than 50% of the network participants it can be assumed that the block is now written to the blockchain. Due to different race conditions, however, it is recommended in praxis to wait until consecutive blocks are attached to the block we are interested in. Once it is no longer the newest block on the chain we can assume that it is secure. The security of our information increases with every block that gets attached. And that is why the ledger is called blockchain. Now it is also easy to see why adding information is perfectly fine but changing information is not. Changing or deleting information would break the link between the blocks and destroy the chain, this property of the blockchain is a cryptographical one and out of scope for this blog entry.
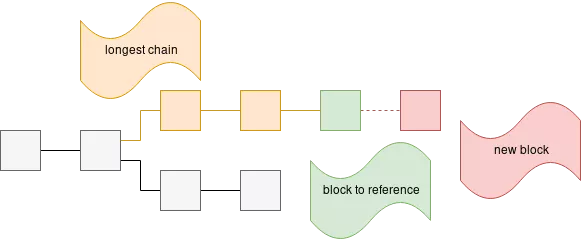
To recap, the blockchain is a distributed ledger and whenever someone wants to add an entry to this ledger the whole network of participants has to agree on the fact that this entry was added. However, once it is added this entry is secure and can not be changed anymore due to the distributed nature of the blockchain. For the primary use of the blockchain, financial transactions, this is mainly to solve one major problem, the one of double spending. Once you have transferred money to someone else you can not take back this money or transfer the same money to another person. As interesting and necessary as this is for a cryptocurrency to function it opens a lot of possibilities for other use cases.
If we think back to the last blog entry, data provenance has one big problem, namely the need for a trusted provenance store. If we can, however, map the information which is saved in the provenance store to the blockchain or even save it entirely into the blockchain we suddenly move the issue of safeguarding the data in this store to a place which is per design safe from manipulation. Of course, this is not entirely true, as briefly mentioned, one blockchain is only as secure as the currency which builds on top of it is stable however for our use case we can speak of a relatively high safety. This removes a lot of unnecessary complexity from our data provenance model and allows us to focus on the more important task at hand, properly collecting the provenance information.
Svetoslav Videnov

My master thesis aims to combine the advantages of the blockchain with data provenance. The blockchain is a distributed ledger which allows persisting data in an unchangeable way. Data provenance is an approach to track what happened to data and by this allowing to build trust into this data.
