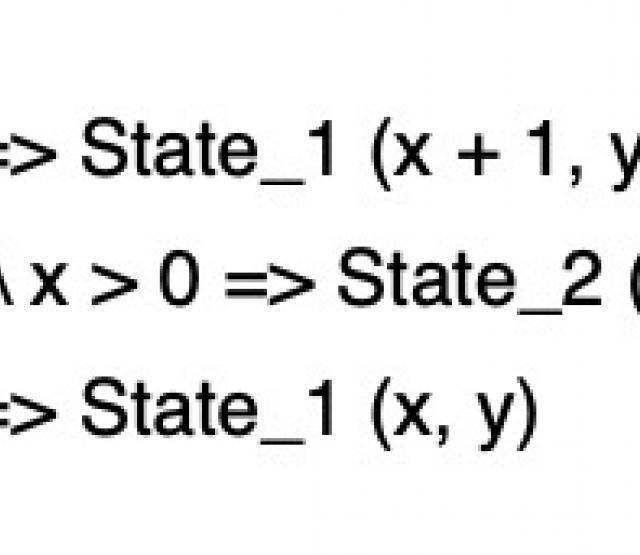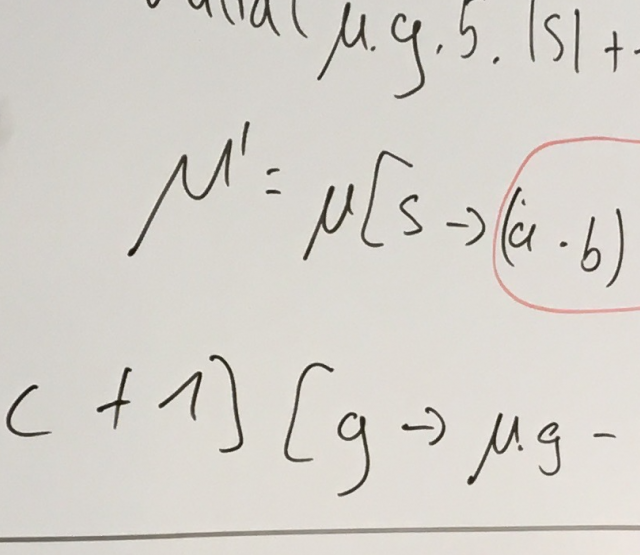
Förderjahr 2017 / Project Call #12 / ProjektID: 2158 / Projekt: EtherTrust
Prototypen können sehr nützlich sein um die allgemeine Praktikabilität eines Ansatzes zu testen. Was lernen wir aus dieser Arbeitsphase für EtherTrust?
Hallo zusammen,
In unserem letzten Beitrag haben wir euch etwas über unseren ersten Prototyp für EtherTrust erzählt. Heute wollen wir ein bisschen genauer auf die Probleme eingehen, die beim Entwickeln des Prototypen aufgetreten sind.
Die größte Herausforderung unseres Projektes ist es, dass wir zum einen eine wohl wasserdichte Theorie liefern, aber gleichzeitig auch ein effizientes Tool erstellen wollen. Wie im Beitrag über die abstrakte Semantik berichtet, besteht die Gratwanderung dabei hauptsächlich darin, eine Abstraktion unserer Semantik zu finden, die die konkrete Ausführungssemantik eines Vertrages soweit abstrahiert, dass ein SMT-Solver Anfragen zu abstrakten Sicherheitseigenschaften effizient lösen kann, die aber gleichzeitig nah genug an der konkreten Semantik ist, um möglichst viele sichere Verträge auch tatsächlich als sicher beweisen zu können. Das ist in der Praxis leider gar nicht so einfach, unter anderem, weil man zunächst die gesamte abstrakte Semantik implementiert haben muss, um auf echten Verträgen testen zu können, ob Sicherheitsanfragen denn auch effizient gestellt werden können.
Dies macht das Experimentieren mit unterschiedlichen Versionen der abstrakten Semantik sehr schwierig umsetzbar: Änderungen sind immer mit einem sehr großen Implementierungsaufwand verbunden.
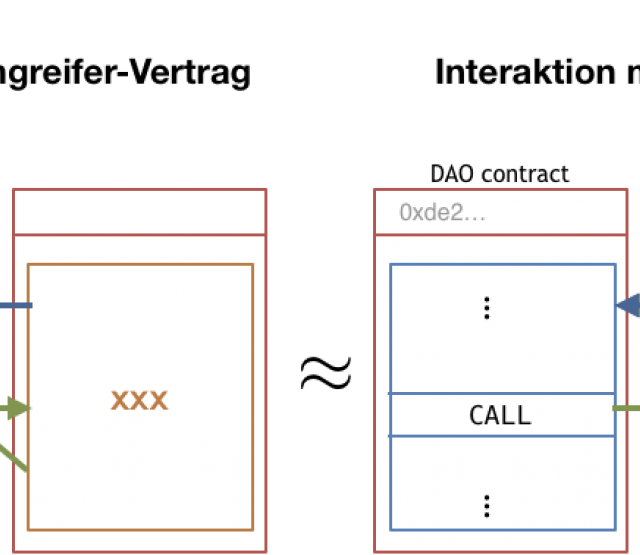
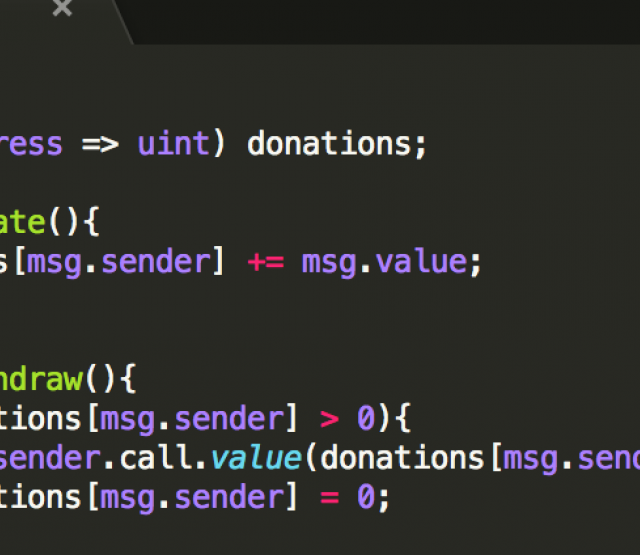
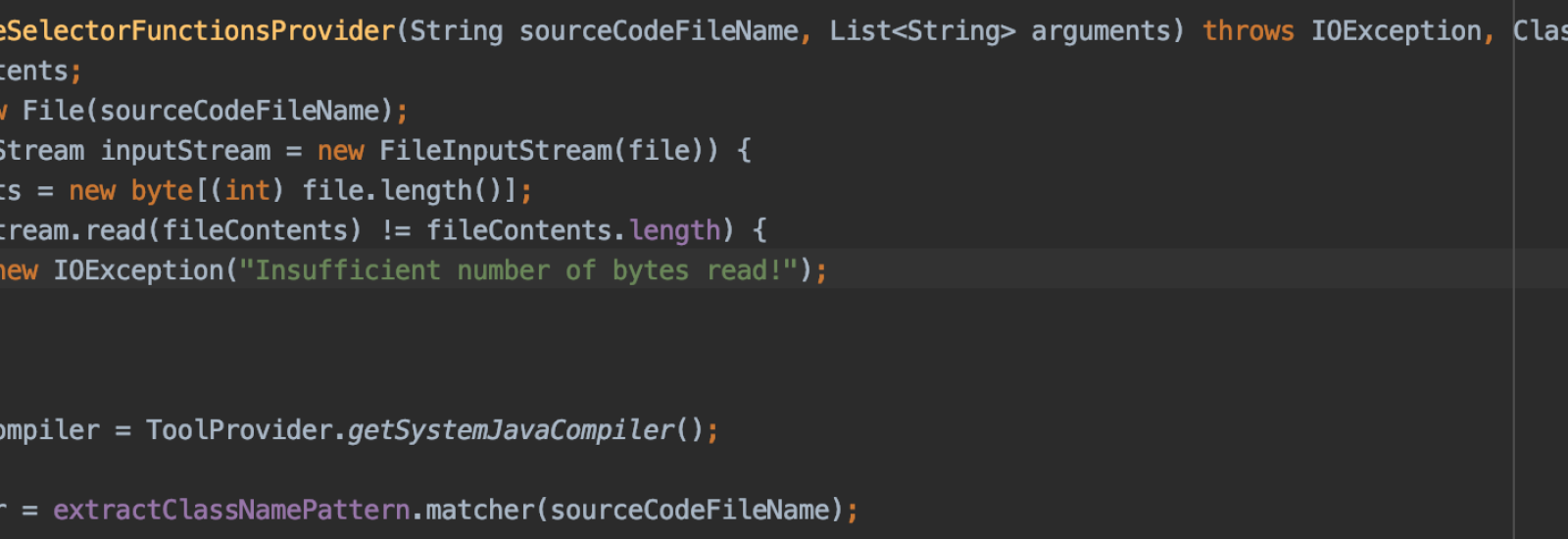
Da wir zum Testen bereits einer sehr umfängliche Funktionalität brauchen, haben wir zudem das Problem, dass der Prototyp selbst schon sehr groß ist, also sehr viel Code umfasst, und damit immer unüberschaubarer wird. Das macht nicht nur die Gefahr von Programmierfehlern im Allgemeinen immer wahrscheinlicher und das Testen schwieriger, sondern führt auch dazu, dass es sehr schwierig ist zu überprüfen, ob denn die abstrakte Semantik, die wir während des Übersetzungschrittes (vgl. letzter Beitrag, Link!) erstellen, tatsächlich unserer Theorie entspricht - schließlich findet sich diese Übersetzung irgendwo tief in unserem Code und ist in Java geschrieben.
Das widerspricht aber leider unserer Idee, dass wir eine große Gewissheit in die Korrektheit und die Sicherheitsgarantien unseres Tools haben wollen!
Um dieses Problem zu lösen, wollen wir unsere Implementierung komplett neu gestalten, sodass die Spezifikation unserer Semantik unabhängig vom Java-Code des Tools ist. Das bedeutet einen großen zusätzlichen Aufwand, da wir nun eine neue Spezifikationssprache benötigen, in der wir die abstrakte Semantik schreiben können. Aber wir denken, die zusätzliche Sicherheit, die wir dadurch gewinnen, ist den Aufwand absolut wert :). Außerdem wird es so auch anderen Wissenschaftlern und Entwicklern einfach möglich sein ihre eigene abstrakte Semantik zu schreiben oder unsere zu erweitern. Wir glauben, dass dies dem Open-Source-Gedanken am meisten entspricht.
Bis zum nächsten Mal!
Euer EtherTrust Team