
Förderjahr 2017 / Stipendien Call #12 / ProjektID: 2180 / Projekt: Automatisierte Generierung von personenbezogenen Passwortlisten
Nun haben wir alle Tweets einer Person gesammelt, aber woher wissen wir, welche Wörter davon für die Erstellung von Passwörtern interessant sind?
“Herzlichen Glückwunsch. Sie haben gerade alle 3287 Tweets einer Person extrahiert!”
Und jetzt?
Schnell wird klar, dass das reine Sammeln von Informationen nicht zielführend ist und es auch ein “zu viel” an Daten gibt.
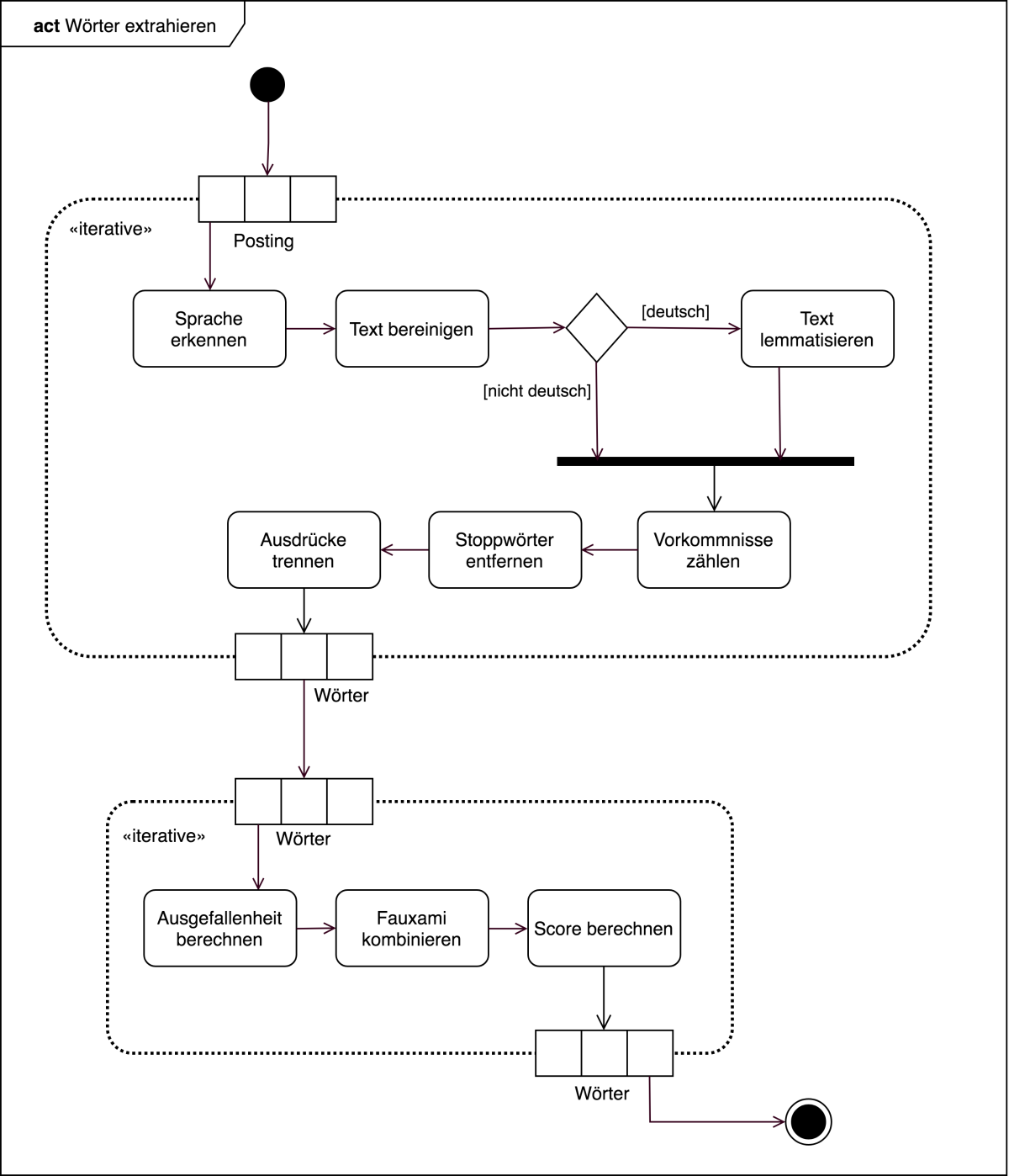
Abbildung 1 zeigt ein UML-Aktivitätsdiagramm, welches den Prozess der Wortextraktion beschreibt. Dabei wird über alle extrahierten Postings iteriert und seriell die folgenden Schritte durchgeführt: Spracherkennung, Textbereinigung, Entfernung von Stoppwörtern, Trennung von Ausdrücken in Kategorien, Lemmatisierung (falls das Posting in deutscher Sprache geschrieben ist) und Zählen der Vorkommnisse des Wortes. Das Ergebnis dieser Kette von Prozessen ist eine Liste an Ausdrücken, die in die Kategorien “Wort”, “Zahl” und “Datum” fallen können. Die Wörter werden anschließend in einem zweiten iterativen Verfahren weiterverarbeitet. Die Schritte umfassen dabei das Berechnen der Ausgefallenheit von Wörtern, das Kombinieren von sogenannten Fauxami und das Berechnen eines Scores.
Spracherkennung
Die Erkennung der richtigen Sprache ist für die weitere Verarbeitung der Daten essentiell. Da viele Menschen multilingual sind, muss jedes Posting einzeln untersucht werden.
Das verwendete Sprachmodell klassifiziert die Postings nach einer zweistelligen ISO 639-3 Abkürzung, welche anschließend in den englischen Langnamen der Sprache transformiert wird.
Textbereinigung
Sonderzeichen, unnötige Leerzeichen, URLs, … All das ist für unsere Zwecke nicht von Bedeutung und wird entfernt. Außerdem werden sogenannte “Stoppwörter”, also besonders häufige und unwichtige Wörter wie Artikel oder Konjunktionen, herausgefiltert.
Lemmatisierung
Das Lemma ist die Grundform eines Wortes. Gerade in der deutschen Sprache gibt es besonders viele deklinierte Wörter und für die Erstellung von Passwörtern ist es wichtig, automatisiert etwa aus “Hunden” das Wort “Hund” zu machen. Dieser extrem spannende Prozess ist jedoch komplex und verdient einen eigenen Blogpost!
Berechnen der Ausgefallenheit
Je spezialisierter ein Wort ist, desto wahrscheinlicher ist es, dass es für ein Passwort verwendet wird. Daher ist ein Wort wie “Falco” als wertvoller einzuschätzen als “Ball”. Mit Hilfe von Häufigkeitsanalysen von Wörtern im Wortschatz von verschiedenen Sprachen, kann die Ausgefallenheit eines Wortes bestimmt werden. Dieser Schritt beinhaltet eine Menge Mathematik und wird ebenfalls in einem zukünftigen Blogpost genauer beleuchtet werden.
Vereinigung von “Falschen Freunden”
Sogenannte “Fauxami” oder “Falsche Freunde” sind Wörter, die in verschiedenen Sprachen vorkommen, aber unterschiedliche Bedeutung haben. Diese Paare können auch in leicht unterschiedlich geschriebener Form auftreten, wobei für den Zweck dieser Arbeit ausschließlich idente (abgesehen von der Großschreibung) Fauxami von Interesse sind. Ein Beispiel für so einen "Falschen Freund" ist etwa das deutsche Wort "Gift", das im Englischen ein Geschenk bezeichnet.
Bei der Behandlung von Fauxami werden die Werte der beiden Ausgefallenheiten verglichen und die Vorkommnisse des niedrigeren zum höheren addiert bevor ersteres dann verworfen wird. So wird sichergestellt, dass kein Wort doppelt vorkommen kann und wichtigere Wörter weiter oben in der Liste stehen.
Ich hoffe, dieser Einblick konnte euer Interesse wecken und ihr schaut im März wieder vorbei, um mehr über die Hintergründe dieser Schritte zu erfahren.

