
Förderjahr 2017 / Project Call #12 / ProjektID: 2099 / Projekt: Searchitect
Alice und Bob lesen gemeinsam netidee Blogeinträge beim Morgenkaffee. Plötzlich meint Alice: "Würde mir eine Applikation anbieten meine Daten zu verschlüsseln..."
... und ich hätte gleichzeitig die Option darauf zu suchen ohne diese zu entschlüsseln, wäre ich skeptisch. Weil sichere Verschlüsselungsverfahren verhindern, dass Rückschlüsse auf den Klartext gemacht werden können!" Bob kratzt sich am Kopf und fragt sich: "Wie ist eine sichere Suche auf verschlüsselten Daten dann trotzdem möglich?"
Bis jetzt sind wir Alice und Bob und auch Euch die Frage wie sich eine sichere Suche auf verschlüsselten Daten gestaltet noch schuldig geblieben und hoffen diese hiermit klären zu können. Falls das weitere Fragen aufwerfen sollte, scheut Euch nicht einen Kommentar zu posten oder uns eine Mail zu schicken.
In Searchable Encryption Verfahren sucht der Server im Auftrag des Users auf den verschlüsselten Daten, ohne diese zu entschlüsseln. Die Verwendung solcher Verfahren ist für die Auslagerung von Daten in die Cloud oder zur gemeinsamen Nutzung von verschlüsselten Daten in der Cloud gedacht. Im Bezug auf Privacy ist das deshalb so wichtig, weil es in großen Verteilten Systemen schwierig ist die Daten geographisch zu lokalisieren. Außerdem werden fast täglich Sicherheitsbrüche bezüglich der Datenspeicherung in der Cloud veröffentlicht, somit kann dem Server oder dem Cloud Service Anbieter nicht vertraut werden und er ist Teil des Gefahrenmodells.
Wie funktioniert Searchable Encryption: In fast allen Schemata wird neben der herkömmlichen Dokumentenverschlüsselung, die verschlüsselte Suche durch einen zusätzlichen verschlüsselten Index ermöglicht. Dieser beinhaltet die Zuordnung von Schlüsselwörtern zu Dokumenten, meist in Form der aus den Schlüsselwörtern deterministisch erstellten Token und Dokument Bezeichner Paaren.
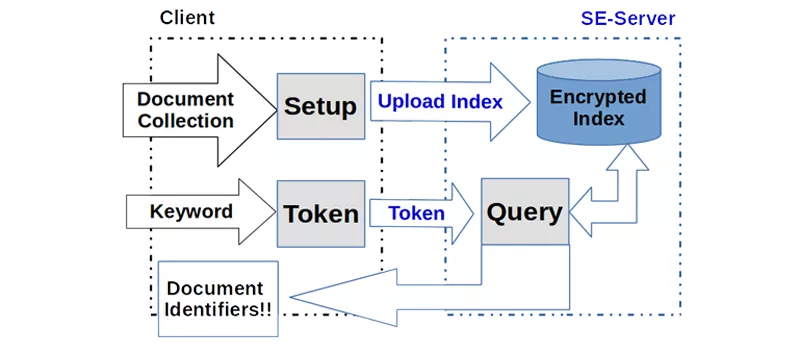
Ein symmetrisches statisches Verfahren wie in der Abbildung dargestellt, besteht aus folgenden drei Komponenten.
- Setup: Das Setup erfolgt durch den Client unter der Angabe eines zu indizierenden Verzeichnisses durch den User. Zuerst wird das nötige Schlüsselmaterial generiert. Anschließend werden alle Dokumente eingelesen und die Schlüsselwörter oder Suchwörter extrahiert, dabei werden alle anderen Wörter wie Bindewörter und Artikel oder Duplikate von Wörtern entfernt. Mithilfe des Schlüsselmaterials wird ein verschlüsselter Index erstellt und auf den Server hochgeladen.
- Token: Will ein User nach einem Schlüsselwort suchen, erstellt der Client mit dem Suchbegriff und dem Schlüsselmaterial ein Token und sendet es an den Server.
- Query: Der Server beantwortet die Anfrage indem er einen Suchprozess auf den verschlüsselten Index durchführt und sendet die gefundenen Dokumenten Bezeichner zurück.
Obwohl sich das auf einem so hohen Abstraktionsniveau sehr einfach darstellt, gibt es eine Vielzahl von unterschiedlichen Verfahren. Diese haben sich in dem Widerspruch und den Abhängigkeiten von Funktionalität, Effizienz und Sicherheit entwickelt. Leider bisher mit der Unvereinbarkeit alle drei auf einmal zu erfüllen. Die größte Unterteilung in zwei Entwicklungsstränge basiert auf der Anzahl derjenigen, die Indexeinträge und somit Inhalte erstellen können. Im einfachen Fall kann nur eineR den Index erstellen, diese Verfahren beruhen auf symmetrischen kryptographischen Primitiven und sind im weiteren Fokus dieses Projekts. Im letzteren Fall werden asymmetrische kryptographische Verfahren verwendet damit mehrere User Inhalte generieren und teilen können, leider sind die dafür verwendeten Algorithmen wie Pairing basierte Kryptographie bisher noch zu ineffizient. In beiden gibt es die Erweiterung in der Anzahl der User die Suchen dürfen, das führt zur Unterscheidung in Single- oder Multi-User Schemata.
Ein kurzer Abriß zur Entwicklung verschlüsselter Indizes:
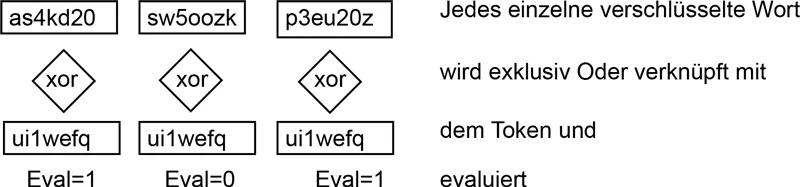
2000 wurde das erste Searchable Encryption Verfahren von Song et al. veröffentlicht. Dieses besteht aus einer deterministischen Volltextverschlüsselung pro Wort ohne Index, durch das Darauflegen einer zusätzlichen Evaluierungsschicht (XOR) konnte der Server für jedes Wort festellen, ob ein Treffer gefunden wurde. Verfahren die auf so einem Prinzip basieren, verraten zudem die Position der Schlüsselwörter.
2003 stellte Goh das erste Indexbasierende Verfahren vor. Dieses bestand aus einem Index pro Dokument, der Server kann dabei mit dem Token für jedes Dokument prüfen ob ein Schlüsselwort in dem Index vorhanden ist. Goh verwendet eine Bloom Filter Datenstrukur um die Tokens zu verstecken, deshalb sind auch False Positive in den Resultaten möglich.
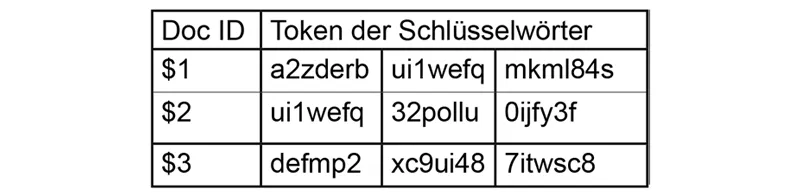
2006 erfolgte die erste Veröffentlichtung eines Schemas mit optimaler Suchzeit durch einen invertierten Index von Curtmola et al. Dabei wird bei einer Suche mit dem Token auf alle Dokument Bezeichner der Dokumente, die das Suchwort enthalten, direkt getroffen.

Dynamische Verfahren erweitern das eingangs vorgestellte statische Schema um eine Update Funktion, darüber können praktischerweise zusätzliche Dokumente hinzugefügt werden. Weitere Verfahren ermöglichen mehr Optionen in der Suche wie konjunktive (UND) oder disjunktive (ODER) Verknüpfungen von mehreren Suchwörtern oder sind optimiert auf Datenbank Abfragen.
Bob strahlt und sagt zufrieden: "Na siehst du, das nennt sich Privacy, der Server kennt und braucht die Schlüssel des Users nicht um auf den verschlüsselten Daten zu suchen. Zero knowledge für dem Server!!" Alice bleibt skeptisch und kontert: "Das beweist noch nicht, dass der Server oder ein Angreifer, der den Server kontrolliert, keine Informationen aus wiederholten Suchvorgängen ziehen kann. Ich werd mal Eve fragen, vielleicht weiß Eve ja mehr zu möglichen Angriffen."








