
Förderjahr 2021 / Stipendien Call #16 / ProjektID: 5900 / Projekt: Synthetic Content for Probe-Resistant Proxies
The big picture
After setting the basis on what keywords should be avoided when creating synthetic content for censorship circumvention purposes, it was time to find an automated process of creating the website and the content for it. As mentioned in my previous blog, the initial idea was to use Jekyll templates as the base skeleton of the website and populate it's content by using models like GPT-3. However, during my research I decided to ditch this approach and solely focused on creating the skeleton using GPT-3 as well. The main reason behind this change is the fact that using GPT-3, provides access to a large pool of ideas and designs, leading to greater creativity and uniqueness in the final website. This is in contrast to using pre-made Jekyll templates, which may lead to a monotonous and predictable look across multiple websites.
In this experiment, the goal was to showcase the capabilities of GPT-3 in website creation. To achieve this, an account was registered at OpenAI's website to generate an API key, which would allow for sending requests to GPT-3 programmatically. The OpenAI Python library was used in this experiment and it provided several modules, including openai.Completion, openai.Code, and openai.Image.
The openai.Completion and openai.Code modules were utilized to generate the HTML template of a blog-like website, which reflected the Document Object Model (DOM) structure of a real-world blog website. This involved extensive testing of numerous prompts to determine the ideal parameters that would generate a template that could be further parsed without adjusting the parameters for each request.
Once the ideal parameters were determined, a parsing algorithm was developed using the Beautiful Soup library. This algorithm parsed the returned DOM structure and checked for certain HTML tags that would need to be populated with content. The application asked for user input on the general theme of the website and the number of blog entries to be created. Based on this information, the content for the first blog post was generated using GPT-3 and populated in the correct DOM node.
Finally, an image was created using the openai.Image module and embedded inside the content to add more authenticity to the blog. Before generating the image, a request was issued to describe the prompt for the generated blog, which provided information to the image prompt for generating a suitable image.
The experiment
In order to create the ideal prompt for building a website and its accompanying parameters, 320 variations were tested using three different engines. This resulted in an equal number of HTML templates that were compared to find the most suitable and authentic option. The engine option allows for selection of the model to use for the task. For this experiment, text-davinci-003, text-davinci-002, and code-davinci-002 models were chosen.
Each tested model allowed for a maximum of 4097 tokens to generate the output, including input tokens from the prompt. The temperature parameter adjusts the level of creativity in the generated output, with the default being 0.5. A low level leads to more deterministic behavior and repetitive outputs. The best_of option generates multiple results for a single prompt, to be compared afterwards.
It was evident that the code-davinci-002 model was not suitable for this experiment. Although it was designed to generate complex code using a descriptive text prompt, it only handles code creation for one language and cannot generate an HTML structure with embedded CSS, for example.
Although text-davinci-003 was stated to be a more capable model than text-davinci-002, it was the latter model that produced more authentic templates. After comparing all 320 generated websites, the following prompt was chosen for generating the HTML template:
'Create a skeleton that reflects a personal blog website with bootstrap and a responsive design that is optimized for mobile as well. Avoid using navigation bars, all the blog posts should be listed on the main page. Add dummy links to the blog entries. Import all the necessary scripts before the closing body tag, such as jquery, popper and bootstrap.'
A sample website returned by this prompt is shown in the figure below.
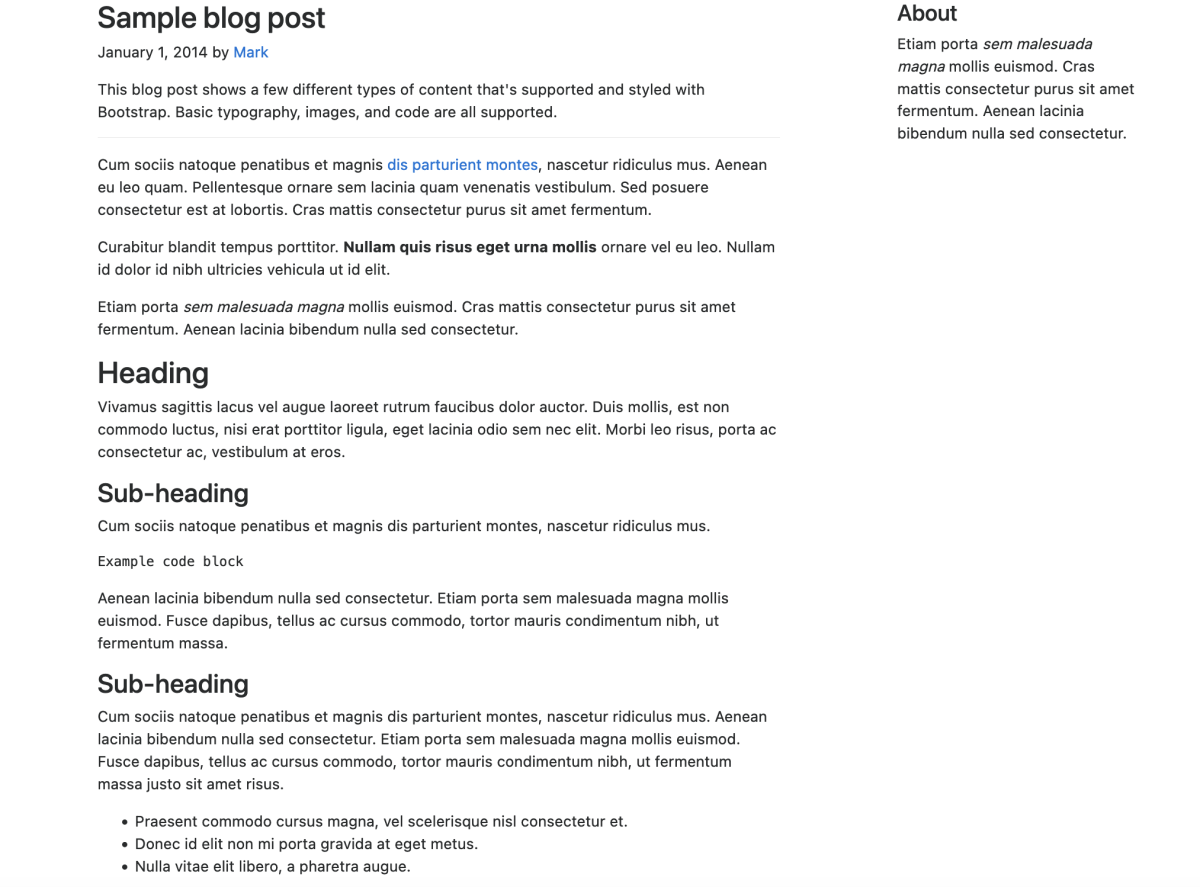
Next, a Python application parses the HTML structure and starts populating the DOM nodes that require additional content. The application then issues a second request to GPT-3, asking for the general topic or theme of the website through a command line prompt. In this case, "social economics" was provided as input, resulting in the prompt:
'Create a blog post for a website that covers the basic topics of social economics and add HTML tags to it.'
The application inserts the content into the placeholder for the first blog post, and to increase authenticity, an image is generated and inserted into the DOM. The previously generated blog content is removed from all HTML tags and inserted into a new prompt to create an appropriate image. GPT-3 determines a short sentence that appropriately describes the blog content. The image module is used to request image generation, with the highest resolution being the default size. GPT-3 provides an URL with the generated image or the option to receive it with Base64-encoding and save it locally. The image is finally inserted within the blog content.

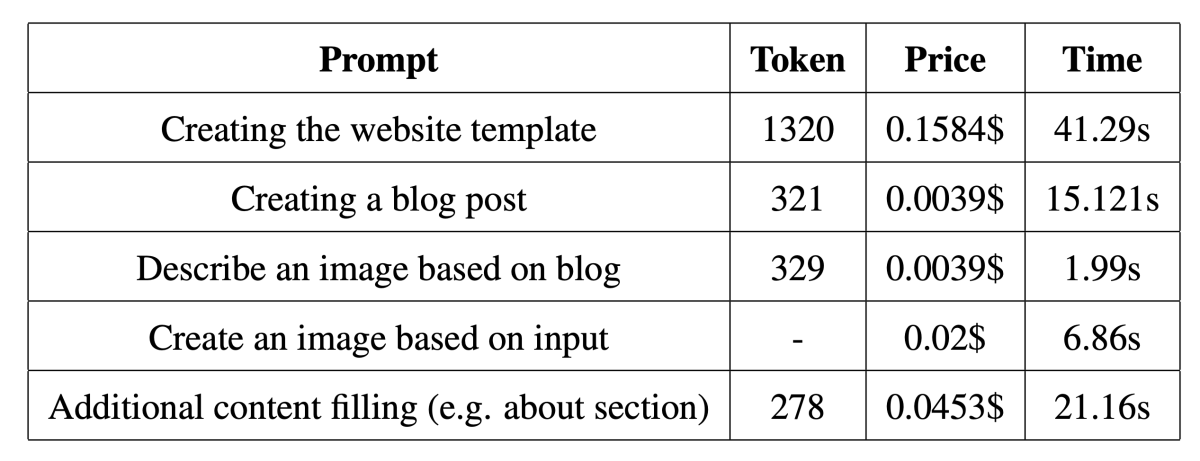
The application allows for repeating these steps multiple times to create multiple blog entries, avoiding generating similar text by using previous entries. The table provides an overview of average tokens used, cost metric based on it, and average execution time for each prompt. The total cost for generating a blog website with one blog entry is around 0.21$, with each follow up blog costing an additional 0.0026$. The prompt using the most tokens and creating the website template also had the slowest execution time.
My research highlights the significant role that advanced AI technologies like GPT-3 can play in the fight against internet censorship by providing powerful tools to those who advocate for freedom of expression and access to information online.
As for future work, there are several ways in which the Python application developed for this thesis can be improved. First, the application can offer more customization options to the user. Additionally, supporting a wider range of website styles could lead to better results. Improving the prompts used to generate text and image content could also be beneficial. Another crucial aspect is to work towards making the application more efficient and cost-effective, which can be achieved through better error handling and reducing API calls.
Lastly, it would be exciting to see the application evolve to support even more complex websites, such as those that contain multiple linked pages and a navigation bar. This could be accomplished by developing the application to generate website structure, in addition to content generation.




