
Förderjahr 2017 / Project Call #12 / ProjektID: 2200 / Projekt: BlockNinjas
Wir wollen hier einen Einblick in die Datenbankstruktur hinter blockninjas geben. Bereits in einem vergangenen Post haben wir beschrieben, wie die Daten in der Bitcoin Blockchain aufgebaut sind. Diese Daten dienen uns als Grundlage. Wir erweitern und verändern diese Struktur allerdings um einen optimierten Zugriff darauf zu bekommen.
Grundsätzlich orientiert sich unser Modell an dem von Bitcoin selbst. Allerdings haben wir aufgrund von Performancegründen einige Daten zusätzlich in Tabellen ausgelagert. Um nun zu den einzelnen Tabellen zu kommen:
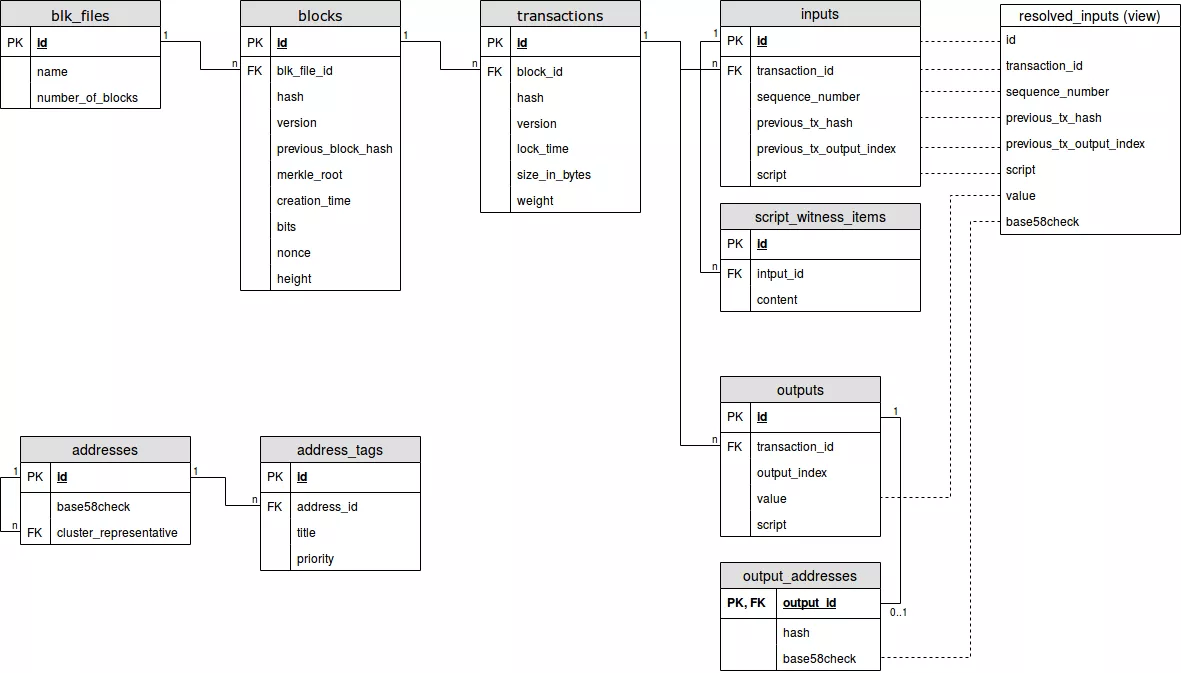
blk_files
Diese Tabelle beschreibt, welche .blk-Dateien von den Bitcoin Rohdaten eingelesen wurden.
blocks
Wie der Name schon sagt, werden hier die Blöcke, aus der die Blockchain besteht, gespeichert.
transactions
Hier werden die Transaktionen, welche vom Bitcoin Netzwerk generiert werden, gespeichert.
inputs
Da jede Transaktion einen oder mehrere Inputs enthält, werden diese natürlich in eine neue Tabelle gespeichert.
outputs
Analog zu den Inputs gibts auch die Tabelle “outputs”.
script_witness_items
Wichtig zu wissen ist, dass seit der Einführung von SegWit Transaktionen, zusätzliche Daten in der Blockchain gespeichert werden. Diese s.g. Witness-Daten speichern wir in dieser Tabelle.
output_addresses
Wie schon oftmals erwähnt, muss die Bitcoin-Adresse aus den Daten, die im Feld outputs.script gespeichert sind, berechnet werden. Diese Adresse, die berechnet wird, ist im s.g. Base58Check Format. Diese wird hier in dieser Tabelle gespeichert. Anzumerken ist, dass diese Adresse lediglich ein Hashwert ist, der base58 encodiert wird. Der zugrundeliegenden Hash wird ebenfalls in dieser Tabelle gespeichert.
addresses
Um nun einen performanten Zugriff auf Adressen zu gewährleisten, speichern wir alle Adressen ebenfalls in diese Tabelle. Im Gegensatz zu output_addresses, kommt in dieser jede Adresse nur genau einmal vor.
address_tags
Da es unsere Software ermöglicht, zu Adressen Tags zu vergeben, speichern wir diese ebenfalls ab. Durch das Attribut “priority” wird definiert, wie wichtig der Tag für diese Adresse ist.
resolved_inputs (view)
Es ist wichtig zu wissen, dass in der Datenstruktur von Bitcoin, keine speichertechnische Relation von Inputs und Outputs gibt. Allerdings ist es so, dass das Feld inputs.previous_tx_hash gemeinsam mit inputs.previous_tx_output_index auf einen spezifischen Output in einer Transaktion referenziert. Da die Blockchaindaten allerdings “sehr groß” sind, kann eine Abfrage, welche diese Relation auflöst, doch etwas länger dauern. Daher haben wir diese View eingeführt. Sie ermöglicht einen raschen Lookup dieser Relation mit weiteren relevanten Daten.








