
Förderjahr 2018 / Stipendien Call #13 / ProjektID: 3793 / Projekt: Data Management Strategies for Near Real-Time Edge Analytics
For novel architectural design of elastic data services, it is fundamental to analyze requirements and dependencies in edge data services together with edge data analytics support.
Edge data services can be considered as strategies, methods, mechanisms and operations for handling and storing constantly generated data at the edge of the network. In this context, three aspects are considered, namely, (1) data/system characterization (e.g., metrics and key properties); (2) application-dependent contexts (e.g., data processing utilities); (3) edge system operations (e.g., elasticity and data importance).
Having complete end-to-end metrics from data sources to data analytics represents the main building block of elastic storage systems
Storage nodes must be aware of edge data workload characteristics. Table 1 summarizes key characteristics. Incoming data might have quality issues due to the presence of missing values or outliers making collected data incomplete. It is important for storage services to decide how to deal with particular incoming data, with the help of metrics such as data quality, data volume and frequency. These metrics can include different statistic techniques for important insights such as anomaly detection. Current status of available capacities from storage nodes must always be up-to-date for efficient management of idle capacities. Hence, the storage service should rely on system characterization metrics. Combination of different metrics from system and data collection processes represents composite metrics and it can uncover useful failure information of underlying infrastructure, leading to proactive decisions on how to collect and store data.

Domain-specific application information can represent direct relation to the storage system
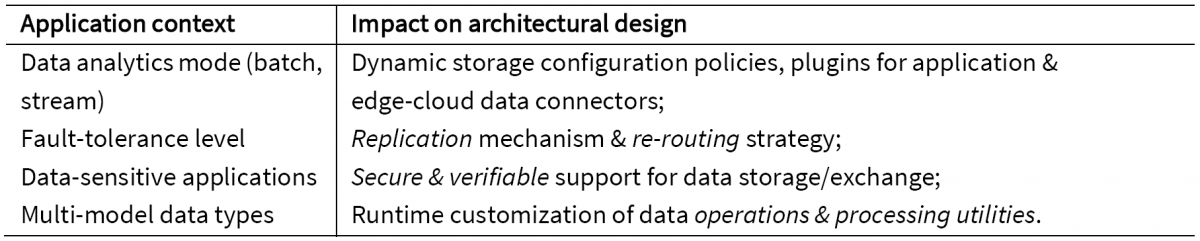
From application-specific context, there are various aspects, such as application information, processing utilities and security, related to edge analytics. Different types of application contexts have strong influence on architectural designs, as shown in Table 2. Based on internal configuration, storage systems map certain data types to sensors. It is important, from the storage standpoint, to know which data types belongs to certain application and what is the nature of IoT data collection, that is, batch or stream data characteristics. Another challenge for edge storage is how to adapt to unpredictable sensor workloads in cases when data collection is related to physical events or periods.
Support from data processing utilities
Novel edge storage service should be supported by different possibilities of data processing utilities that are nowadays overlooked in the storage management research. Possibilities can include data cleaning techniques, anomaly detection, data normalization and different data recovering techniques for missing values and outliers that often appear in distributed IoT systems. Further, predictive maintenance represents another perspective. Performing estimations on future generated data volumes and availability of storage capacities some proactive actions can be taken to improve storage service at the edge such as (1) decide when historical data should be discarded or moved to cloud repository; (2) redirect/move sensor data to another storage node with idle resources.
Security vulnerabilities of sensitive data are overlooked in today's IoT data exchange and storage
Incoming sensor data at the edge often contain sensitive information about the monitored system, raising importance to address data reliability within storage services. Another important aspect is to audit flows of data into the storage and related analytics. Thus, future storage service architectures must consider building verifiable and secure storage of large-scale IoT sensor data such as blockchain technology. However, due to increased data generation, the integration between blockchain and storage must be done in the view that blockchain is only used for selective types of data for verification and auditing purposes.
The data importance nowadays can be changed at runtime asking for adaptation of edging system and service operations
In order to provide reliable edge data storage, elastic storage service should have predefined operations including change in sampling frequency, data filtering operation, functions for efficient data integration from multiple sensors, data sharding operations and data rerouting to interconnected edge storage nodes to avoid storage overhead or network bottlenecks.
IoT systems specify different levels of importance for different types of monitored sensors. Increasing awareness of all previous aspects leads to definition of engineering principles and improving overall designs and implementations for future edge storage strategies and data management.





