Efficient and Transparent Model Selection for Serverless Machine Learning Platforms
Förderjahr 2021 / Stipendien Call #16 / Stipendien ID: 5884
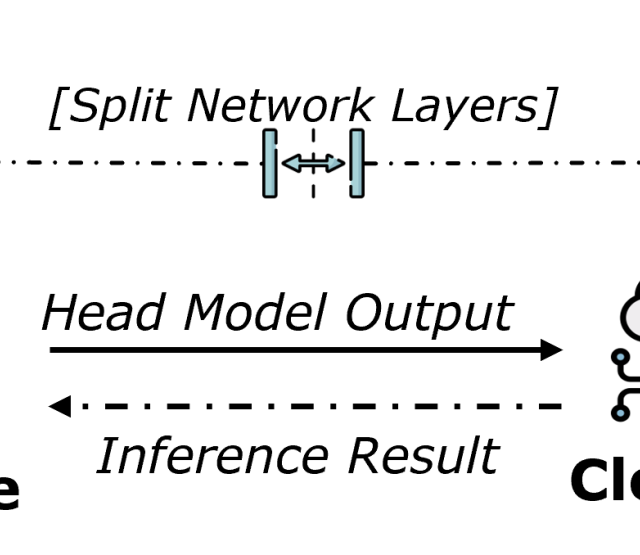
In der Arbeit geht es um den Einsatz von Serverless-Computing im Bereich Machine-Learning. Serverless ist ein neuartiges Ausführungsparadigma, bei dem sich Entwickler:innen nur mehr um das Entwickeln abgekapselter "Serverless Funktionen" kümmern müssen. Aspekte wie Ausführungskontext, Hardwareauswahl und Scheduling werden von der Plattform übernommen. Trotz diesen positiven Aspekten ist Serverless-Computing jedoch noch immer limitierend in innovativen Einsatzgebieten, welche meist datenintensiv sind. Eines dieser Einsatzgebiete ist das Bereitstellen von Machine Learning Applikationen. Diese Limitierung ist aber nicht inhärent zum Paradigma sondern ein lösbares Problem. Deswegen füge ich Metadaten zu den Funktionen bei, welche dann von der erweiterten Plattform aufgegriffen werden. Anhand dieser Metadaten kann die Erweiterung dann entscheiden, welche AI-Modelle bereitgestellt werden, wo die benötigten Daten sind und auf welcher Hardware die Funktion ausgeführt werden muss.
Uni | FH [Universität]
Themengebiet
Zielgruppe
Gesamtklassifikation
Technologie
verwendete Open Source SW
Lizenz