Förderjahr 2021 / Projekt Call #16 / ProjektID: 5762 / Projekt: Lost in Data
Es ist gar nicht so schlimm, wenn Daten oder Auswertungen keine Antwort liefern. Schlimmer ist, wenn sie auch die gleiche Frage jede beliebige Antwort liefern und sich nicht klar argumentieren lässt, welche dieser Antworten falsch ist.
Im Rahmen der Lost in Data-Projekts analysieren wir das Datenrepository des EU Lobbying und Transparenz-Registers. Das Ziel dieser Publikation: Das Verzeichnis sollte Transparenz darüber schaffen, wer in der EU als Lobbyist auftritt – und wofür lobbyiert wird.
Das sind recht klare Fragestellungen – aber dennoch liefert das Register darauf keineswegs klare Antworten. Die Daten sind als recht unstrukturierte Textfiles abgelegt, die sich notdürftig in Spalten aufteilen lassen. Zwischendurch wechseln allerdings Trennzeichen, Formatierungen und auch die Semantik der Einträge ist nicht immer eindeutig.
Das Problem – diese Inkonsistenzen schaffen keine Klarheit für Anwender darüber, wie die Daten konkret zu interpretieren sind. Schon bei einfachen und geradlinigen Fragestellungen führen kleine Interpretationsunterschiede zu völlig unterschiedlichen Ergebnissen.
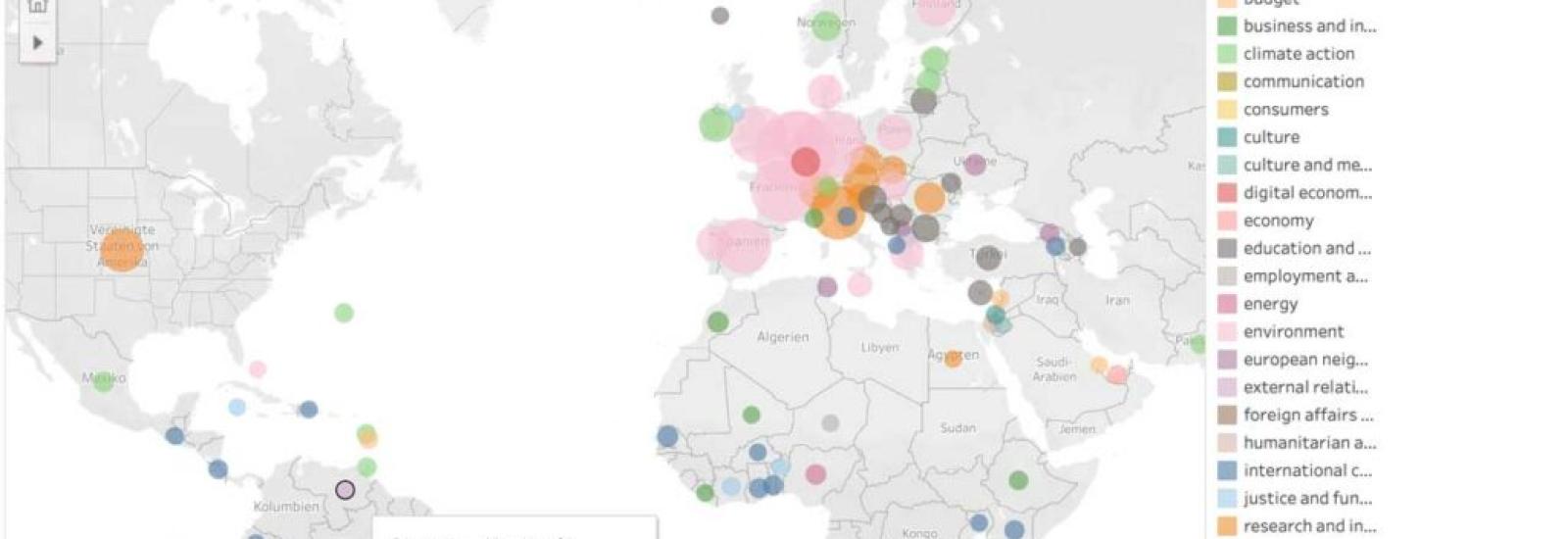
Als Beispiel dazu kann die einfache Frage nach den häufigsten Lobbyingthemen dienen. Anhand der unsauber strukturierten Informationen lassen sich keine klaren Kriterien für Antworten finden – auch die datentreueste Auswertung bleibt Spekulation. Aus den aktuellen Visualisierungen hier zwei Demo-Grafiken: Die Nennung der häufigsten Themen liefert Klima und Umwelt als wichtigste Anliegen (rosa Bubbles). Die Einschränkung der Abfrage auf die 1000 umsatzstärksten Lobbyorganisationen lässt Landwirtschaft und Finanzindustrie als wichtigste Themen übrig. Und keine dieser Auswertungen lässt Rückschlüsse darauf zu, in welchem Zusammenhang Themen und Umsätze stehen – es kann also mit gutem Recht und der gleichen Datengrundlage alles mögliche behauptet werden. Das ist ein Problem, das im Widerspruch zur vermeintlichen Klarheit steht, die Daten versprechen.


Wie kann man mit diesem Problem umgehen?
Ein Zugang ist die Datenerhebung und deren Dokumentation: Gezieltere Fragestellungen und Informationen bei den Daten über die eigentliche Fragestellung helfen, in der Auswertung auf der richtigen Spurt zu bleiben. – Das lässt sich allerdings nicht nachträglich verändern, auch wenn die EU mittlerweile selbst in ihren Open Data-Aktivitäten stark auf Dokumentation und Metadaten setzt. Dazu schreibe ich später noch mehr.
Ein anderer Angriffspunkt ist das Datenmodell. Auch hier sind allerdings Grenzen gesetzt. Schon die ersten vorsichtigen Modifikationen zeigen, dass man recht schnell an Grenzen stösst, wenn die eigentliche Information gesucht wird.
Als kurzer Vorblick sind hier die ersten Varianten von Graphen, ausgehend vom eigentlichen Zustand der Daten hin zu einem wünschenswerten Szenario.




Wie diese Szenarien die Informationsqualität verändern und welche dieser Szenarien unter welchen Einschränkungen zulässig sind, darum wird es in den nächsten Wochen gehen ...

