Förderjahr 2024 / Projekt Call #19 / ProjektID: 7409 / Projekt: KomMKonLLM
Wir beschreiben den Prozess zur Erstellung von Konsistenztests für LLMs mit Hilfe von kombinatorischen Methoden (Teil 2 von 2).
Der erste Teil der Methodikbeschreibung von KomMKonLLM ist hier zu finden: Methodik von KomMKonLLM (Teil 1 von 2) | netidee
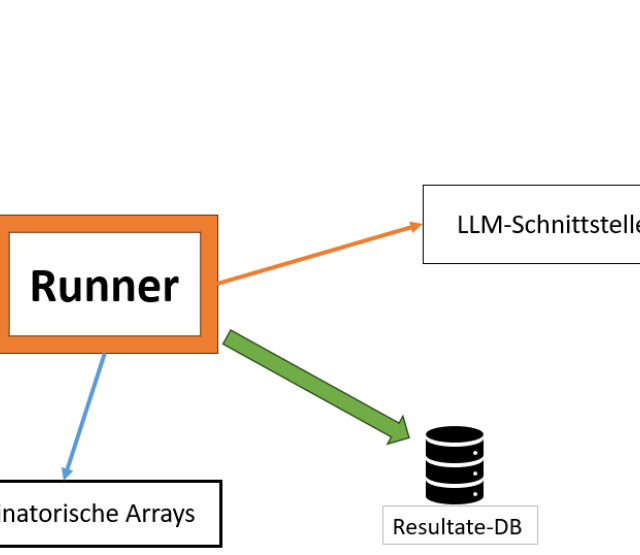
Um kurz zu wiederholen: Das Konsistenztesten von LLMs adressiert das Problem, sicherzustellen, dass LLMs zuverlässig auf verschiedene Eingaben reagieren. In KomMKonLLM wenden wir kombinatorische Testmethoden aus dem Softwaretesten an, um Konsistenztests für LLMs zu generieren. Ausgehend von einer gegebenen binären Entscheidungsfrage, gliedert sich der Gesamtprozess zur Erzeugung von kombinatorischen Konsistenztests in folgende Schritte:

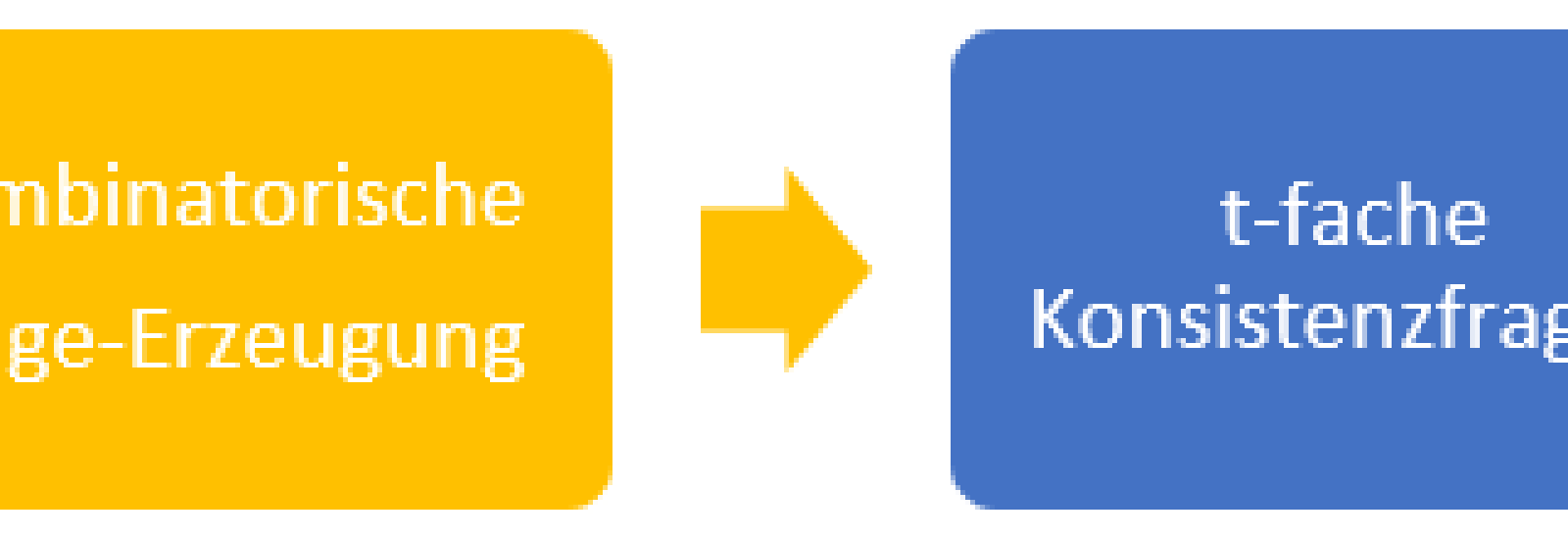
Im vorherigen Blog-Post wurden die ersten drei Schritte in obigem Diagramm beschrieben, nun betrachten wir die letzten drei:
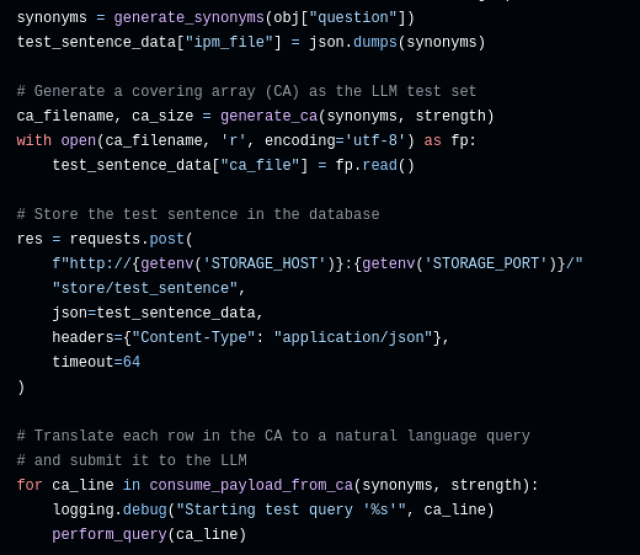
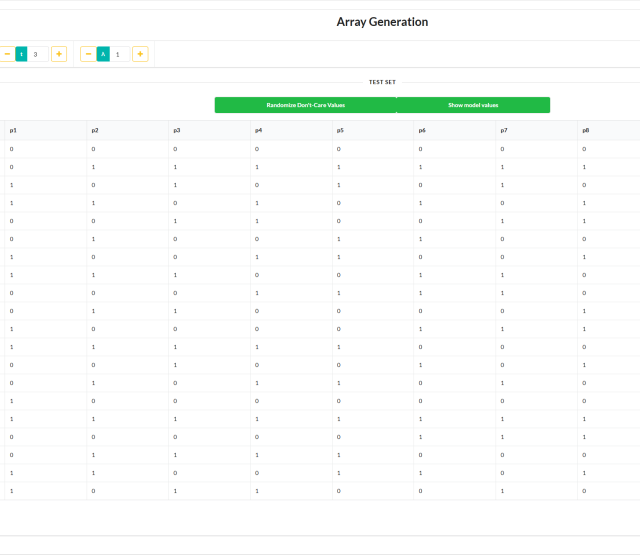
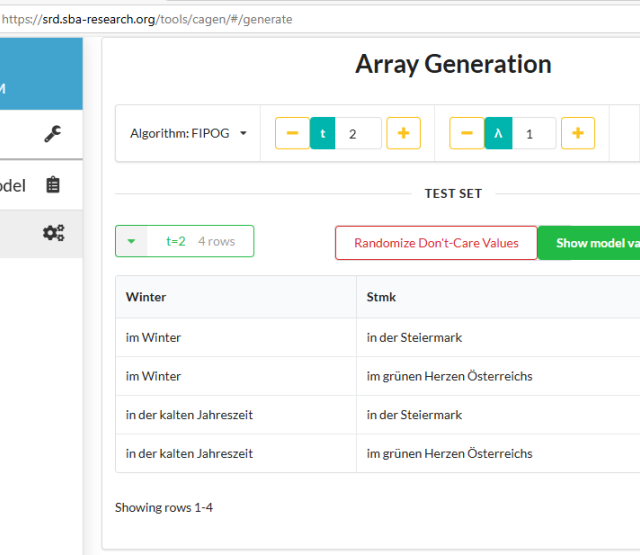
- „t-fache Konsistenzfragen“: Jede Zeile der im vorherigen Schritt erzeugten Array-Struktur kann nun wieder in eine Frage zurückgeführt werden, indem die Wörter durch ihre in der Zeile angegebenen Synonyme ersetzt werden. Dadurch erhält man nun kombinatorisch erzeugte abgewandelte Fragen, welche t-fache Diversität in der Synonymersetzung bieten.
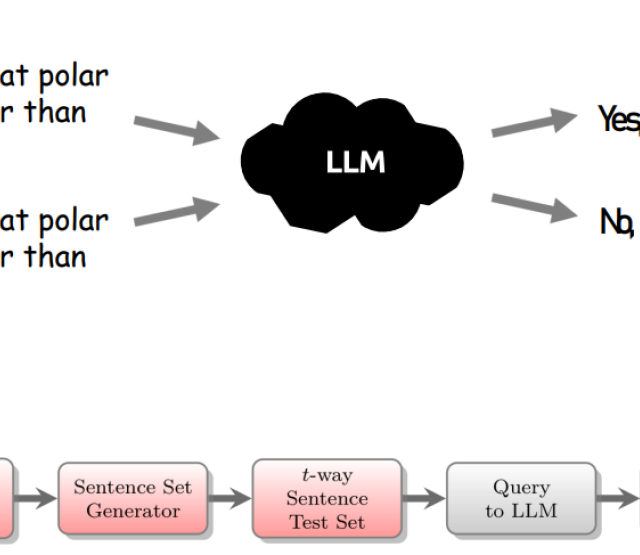
- „Anfrage an LLM“: Jede der so erzeugten Fragen wird nun mit einem speziellen Prompt, der eine binäre Antwort des LLMs forcieren soll, an ein LLM gesendet und das Frage-Antwort Paar in einer Datenbank gespeichert. Aufgrund der Beschaffenheit der ersten Zeile der verwendeten abdeckenden Array-Struktur wird die ursprüngliche Frage als Erstes an das LLM gestellt.
- „Auswertung der Antworten“: Alle Frage/Resultat-Paare, welche basierend auf der abdeckenden Array-Struktur erstellt wurden, sind in der Datenbank verfügbar. Unter der Annahme, dass Synonymersetzungen die Semantik – und daher insbesondere auch die entsprechende (richtige) binäre Antwort – nicht verändern, ergibt sich die Konsistenzevaluierung nun aus dem Vergleich aller gespeicherten Resultat-Werte, welche – im besten Fall – alle gleich sein sollten. Sollte dies nicht der Fall sein, werden die abgewandelten Fragen mit abweichender Antwort aufbereitet dargestellt. Man beachte, dass dieser Vergleich für binäre Antworten im “Ja/Nein“-Format direkt implementierbar ist.
Der examplarischen Durchführung dieses Prozesses widmen wir uns in diesem folgenden Blog-Post.
Anmerkungen zum obigen Prozess:
- Für jedes LLM muss ein Prompt gefunden werden, sodass nur binäre-Antworten zurückgegeben werden, sodass die direkte Vergleichbarkeit der Antworten zu verschiedenen (abgewandelten) Fragen sichergestellt ist.
- Der Parameter t, welcher die Diversität im Sinne der gleichzeitigen Synonymersetzungen in Fragen bestimmt, kann als Wertebereich innerhalb der natürlichen Zahlen Werte von eins [1] bis zur maximalen Anzahl an Worten mit entsprechender lexikalischer Kategorie annehmen. Je größer diese (Diversitäts-) Stärke [2] gewählt wird, desto mehr Zeilen haben die sich ergebenden abdeckenden Arrays. Jedoch erreicht man in der Praxis oft für nicht-maximale Stärke abdeckende Array-Strukturen, die immer noch signifikant weniger Zeilen haben als das entsprechende vollständige Kartesische Produkt der Parameter-Wertemenger aller Parameter des betrachteten IPMs.
- Für weitere Informationen zu kombinatorischem Software-Testen verweisen wir auf das "Automated Combinatorial Testing for Software"-Projekt des US NIST und für die in KomMKonLLM implementierte Methodik auf folgenden Konferenzbeitrag.
[1] Im Fall t = 1 sind die Synonymersetzungen für einzelne Worte unabhängig von einander.
[2] In der englischen technischen Fachliteratur oftmals als strength bezeichnet.
Bernhard Garn

Google Scholar: https://scholar.google.at/citations?user=Afk5HBQAAAAJ&hl=en&oi=ao
Bernhard Garn is a research scientist in applied mathematics; senior researcher at the MATRIS Research Group (https://matris.sba-research.org/) at SBA Research (https://www.sba-research.org/).
Research Interests
At the core of Bernhard’s research is the application of discrete mathematics, in particular design theory, to scientific fields. With his background in mathematics, he is especially interested in the application of theoretical results to practical problems, effectively bridging the gap between mathematics and application domains.
His research interests include combinatorial mathematics for software testing, mathematical aspects of information security as well as discrete mathematics for disaster research.
He has developed further the underlying discrete mathematical structures used in combinatorial testing for software from a theoretical perspective using combinatorial and computer algebra techniques. He has also applied combinatorial security testing to several major modern issues in information security, thereby covering different layers of the software stack. In particular, Bernhard has developed CST approaches for web security (XSS, SQLi) and the security and reliability of operating systems. In the domain of online privacy, he has demonstrated how combinatorial methods can be used for browser fingerprinting.
Bernhard is further interested in disaster research, ranging from natural, cyber disasters in critical infrastructure to financial disasters, with the goal of strengthening preparedness and resilience.
Bio
Bernhard received a Bachelor of Science and a Diplomingineur in Technical Mathematics, as well as a Doctoral degree in technical sciences (Informatics) from TU Wien.