Förderjahr 2024 / Projekt Call #19 / ProjektID: 7409 / Projekt: KomMKonLLM
Vom Beispielsatz zum Testset zur normalisierten LLM-Ausgabe: In diesem Eintrag möchten wir kurz erläutern, wie unsere Implementierung von einem Eingabesatz zu einem Set von LLM-Prompts und anschließend zur Verarbeitung der Ausgabe des Modells gelangt
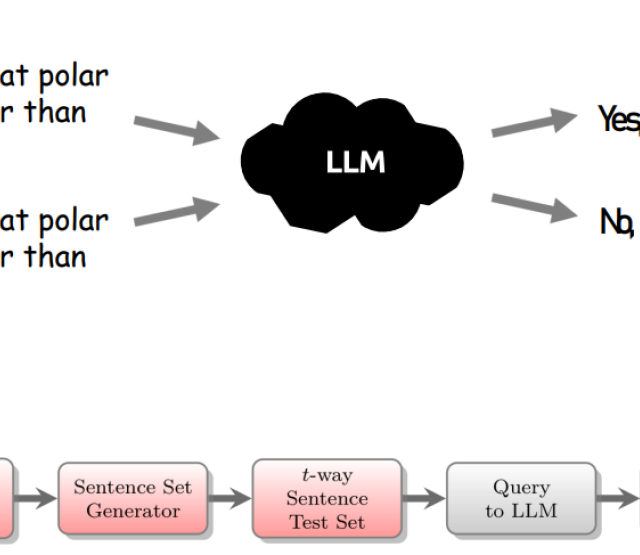
In den vorherigen Blogeinträgen wurde bereits unsere Methodik zum Konsistenztesten von Large Language Models (LLMs) erklärt. Vor kurzem haben wir auch die Implementierung unseres Projekts sowie ein beispielhaftes Datenset zur Evaluierung von LLMs (und deren Ergebnisse bei der Anwendung auf sechs Sprachmodelle) veröffentlicht. In diesem Eintrag möchten wir kurz erläutern, wie wir technisch gesehen von einem Eingabesatz zu einem Set von LLM-Prompts und anschließend zur Verarbeitung der Ausgabe des Modells gelangen.
Generierung von Synonymen
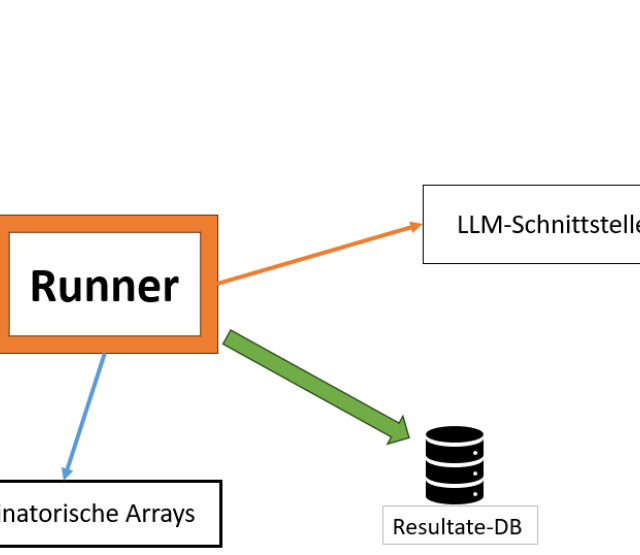
Wir beginnen mit einer ursprünglichen Frage, aus der wir zusätzliche LLM-Eingaben generieren wollen. Unser Runner, welcher den Testablauf koordiniert, ruft dazu zuerst die unten abgebildete Methode auf. Diese verwendet gleich zwei NLP (Natural Language Processing)-Bibliotheken: SpaCy, um den Satz in grammatikalische Bestandteile (hier auch Token genannt) aufzuteilen und deren Funktion innerhalb des Satzes zu ermitteln, und NLTK (genauer gesagt, die Komponente WordNet), um für einige der Tokens Synonyme zu generieren.
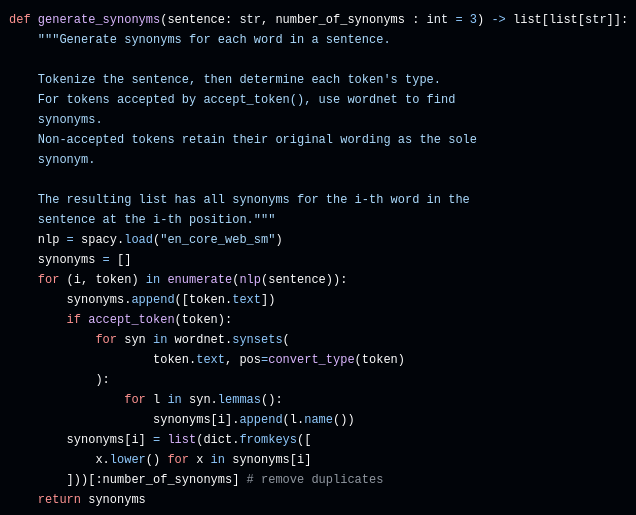
In dieser Methode wird zunächst der Satz in einzelne Tokens aufgespalten. Nachdem wir beim Testen immer zuerst die Original-Version eines Tokens ausprobieren wollen, initialisieren wir die Liste der Synonyme für das aktuelle Token damit.
Nicht alle Arten von Tokens werden mit Synonymen versehen: So macht es etwa keinen Sinn, Namen oder Punktuation durch Alternativen zu ersetzen. Das würde die Bedeutung des Satzes fast garantiert drastisch ändern. Wir filtern deshalb durch einen Aufruf der Methode `accept_token()`, um nur Nomen, Verben und Adjektive zu verändern. Für diese Arten von Token generieren wir mittels WordNet Synonyme und fügen sie zur Liste hinzu.
Am Ende werden die Synonyme noch dedupliziert und ihre Anzahl auf den Wert des Parameters `number_of_synonyms` beschränkt. Die Methode gibt für jedes Token eine Liste von Synonymen aus - mindestens jedoch die ursprüngliche Variante.
Prompt-Generierung
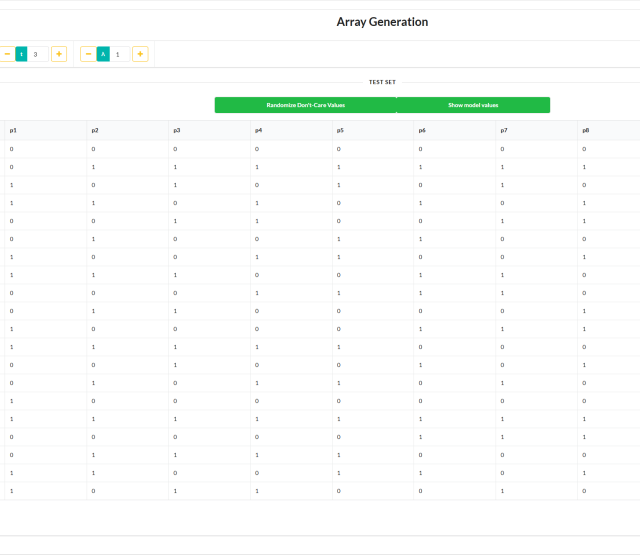
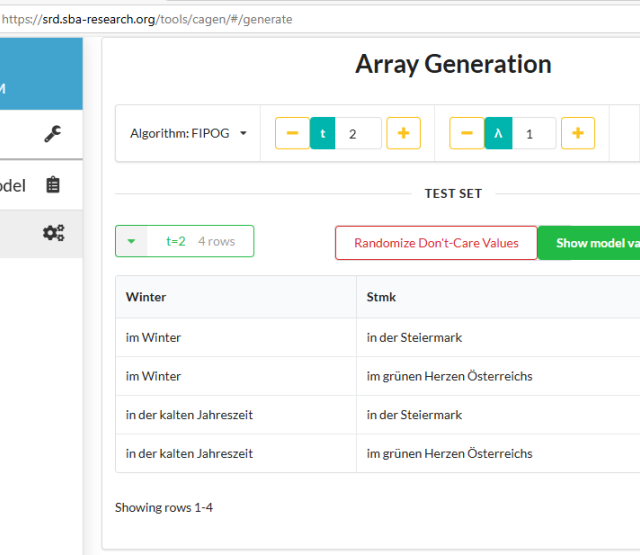
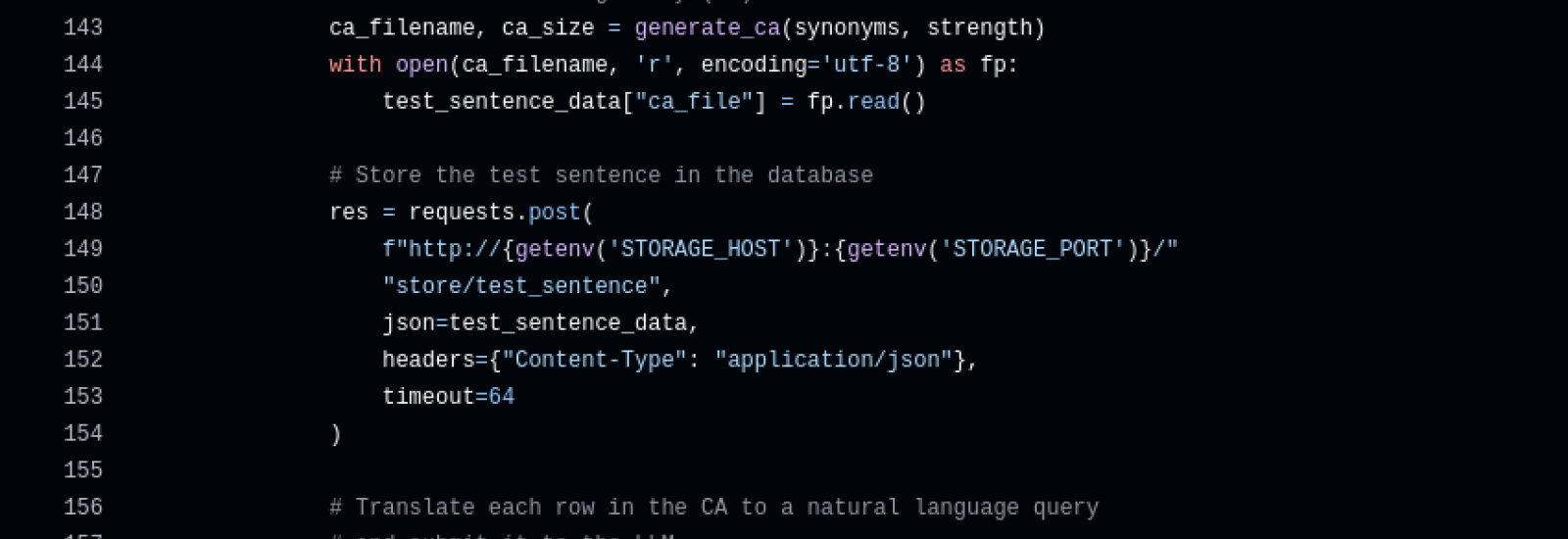
Die beiden Methoden `generate_ca()` sowie `consume_payload_from_ca()` sorgen dafür, dass aus der Liste von Synonymen ein kombinatorisches Test-Set wird. Erstere ruft eigentlich nur einen Wrapper um einen Covering Array (CA) Generator auf - welcher Generator wirklich verwendet wird, wie das dazugehörige Eingabe-Modell aussieht und welche Struktur die Ausgabe des Generators hat, ist der unterliegenden Implementierung überlassen (die befindet sich hier).
Die Methode `consume_payload_from_ca()` ist ebenfalls ein Generator - allerdings ein Python Generator. Das ist eine spezielle Art von Funktion, die mehrmals aufgerufen wird und statt einem `return` (womit normalerweise eine Funktion beendet wird) das Statement `yield` benutzt. Jedes Mal, wenn ein Generator aufgerufen wird, läuft er bis zum nächsten `yield` durch. Der Rückgabewert des Generators wird dann oft in Iteratoren weiter verarbeitet. In diesem Fall gibt unser Generator immer einen String zurück: Beim ersten Durchlauf ist das der ursprüngliche Satz (dafür wird einfach immer das erste Synonym verwendet). Bei jeder weiteren Iteration wird eine Zeile aus dem CA benutzt. Jede Spalte des Arrays steht dafür für ein Token, und jede Zelle bestimmt für den aktuellen Testfall, welches der Synonyme verwendet werden soll.
Aufgrund der Eigenschaften eines CAs erreichen wir mit den so erzeugten mutierten Sätzen immer eine garantierte Mindestabdeckung der möglichen Kombinationen von Synonymen.
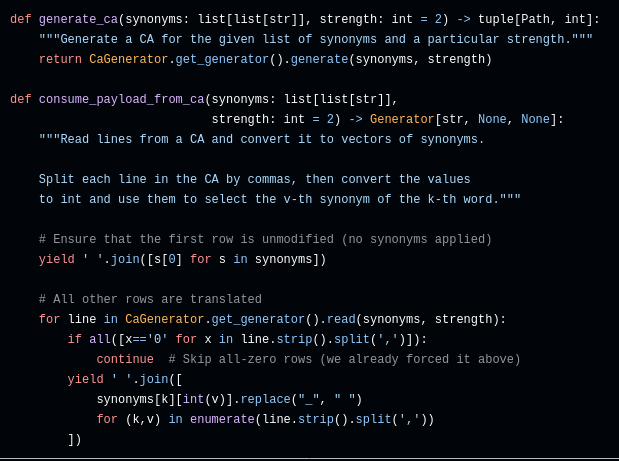
Zu guter Letzt wird noch optional ein Präfix und ein Suffix an den Satz vorangestellt bzw. angehängt, um einen LLM-Prompt zu erhalten. Das ist oft notwendig, um das Modell dazu zu bringen, die Ausgabe richtig zu formatieren bzw. nicht überflüssige Informationen zu inkludieren.
Prompt-Ausführung
Der Runner übermittelt den fertigen Satz nun per HTTP an einen Model Executor. Dieser bietet ein gemeinsames Interface für alle angebundenen LLMs und ermöglicht es dem Runner so, Einstellungen des Modells zu setzen und einen Prompt auszuführen. Die einzelnen Implementierungen der Anbindungen müssen im Hintergrund oft noch weitere Schritte setzen, um etwa Modellparameter auf sinnvolle Werte zu setzen oder Sub-Modelle zu initialisieren. Ein gutes Beispiel dafür ist Ollama:
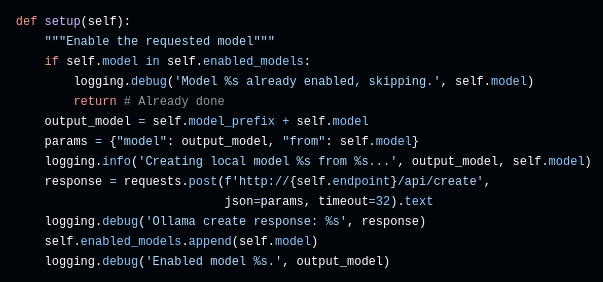
Normalisierung von Ausgaben
Wir unterstützen aktuell ausschließlich Fragen mit boolschen Antworten (also "true oder false"). Sprachmodelle neigen aber dazu, trotz expliziter Anweisungen eine ganze Reihe an unterschiedlichen Formulierungen zu verwenden. Unser Oracle führt deshalb eine Normalisierung durch, bei der überflüssige Zeichen und Worte entfernt und auch sinngemäße pseudo-boolsche Ausgaben (wie etwa "1" oder "yes") richtig uminterpretiert werden.
Damit sind wir bereit für die Analyse - die findet in einem eigenen JupyterLab Notebook statt, das auch zusätzlichen Beispielcode, Kommentare und Visualisierungen beinhaltet. Wie man selbst unser Test-Framework für Konsistenztests von LLMs zum Laufen bekommt - und wie eigene Anbindungen an weiter Modelle und CA-Generatoren implementiert werden können - wird in unserem Repository erklärt.
Manuel Leithner