Förderjahr 2020 / Project Call #15 / ProjektID: 5156 / Projekt: urban_geodata
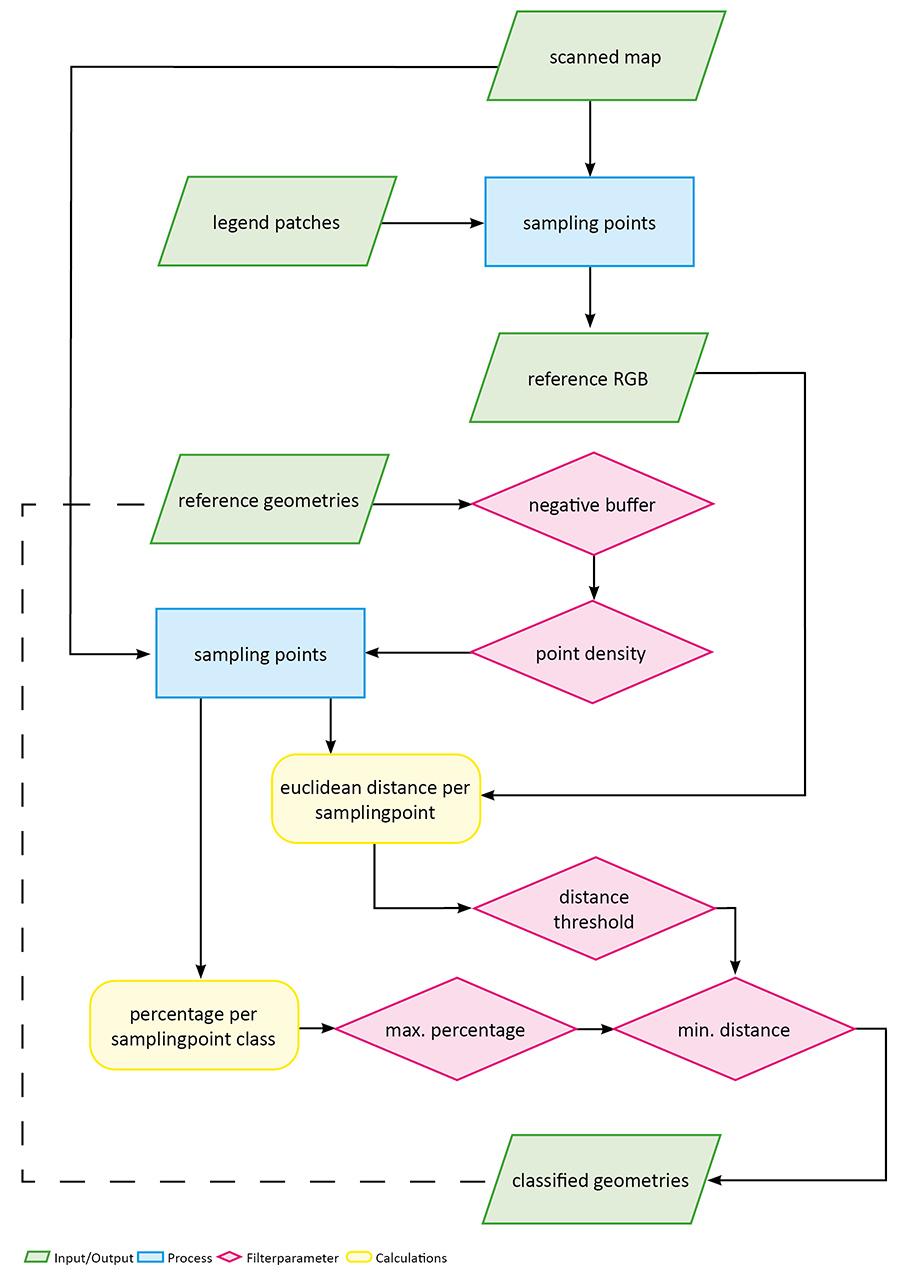
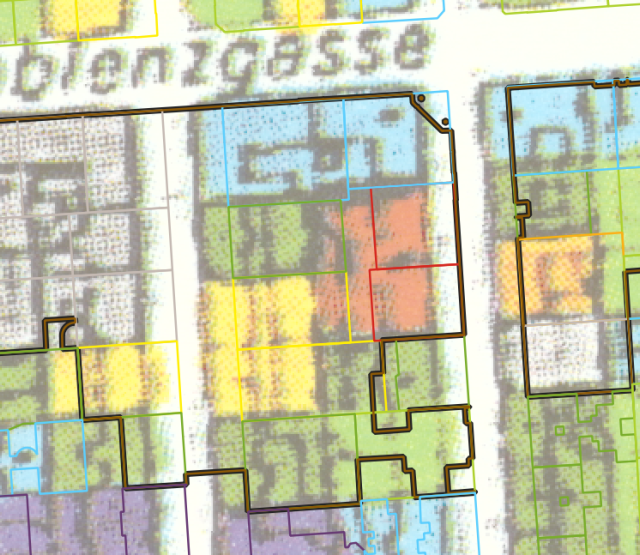
Ein Kernstück des Projekts urban_geodata besteht in der Etablierung eines semiautomatischen Workflows. Dies geschieht bei den thematischen Karten durch ein Script, mit dem die Referenzgeometrien an Hand ihres zuvorgesampleten RGB-Wertes klassifiziert werden. Wesentlich hierbei sind die QGIS-nativen Funktionen zum Einsatz:
- 'RandomPointsInPolygons'
- 'SampleRasterValues'
In Kombination lassen sich mit diesen beiden Funktionen sampling-points für alle Referenzgeometrien erstellen. Die Dichte dieser sampling-points ergiebt sich in Abhängigkeit von der jeweiligen Fläche, wobei sich ein Wert von 0,5 Punkten pro m² als ideal erwiesen hat. Ein entsprechendes QGIS-Modell befindet sich im Repository und ist um den Parameter 'Negativbuffer' erweitert, um eventuelle Offsets zwischen Referenzgeometrie und gescannter Karte zu kompensieren.
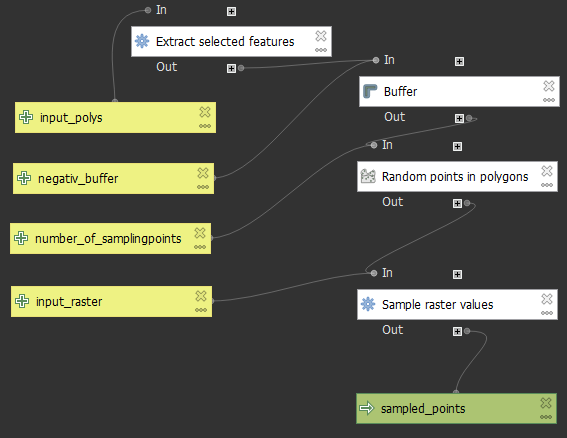
Zeitgleich wird auf gleiche Art und Weise die Legende des jeweiligen Kartenscans digitalisiert. Dadurch ergeben sich Referenz-RGB-Werte für jede Klasse.

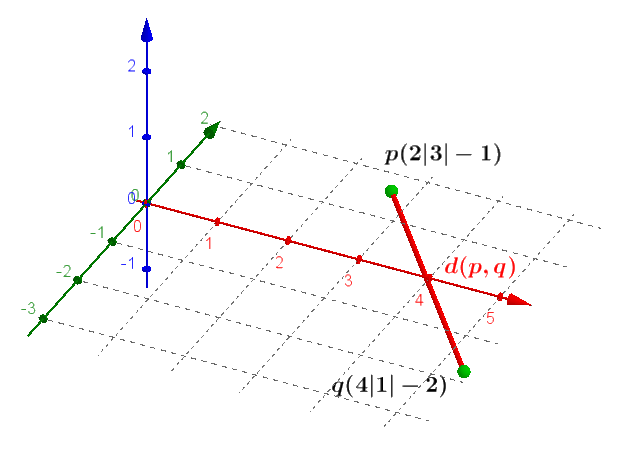
Bei der Weiterverarbeitung werden die RGB-Werte der sampling-points der Referenzgeometrie mit jenen der Legende verglichen. Dabei wird für jeden Punkt die euklidische Distanz zu jedem Referenzwert pro Klasse berechnet:
def euclidean_distance(p1, p2):
return sum((a - b) ** 2 for a, b in zip(p1, p2)) ** 0.5Python-Funktion zur Distanzberechnung zwischen zwei Punkten im dreidimensionalen (RGB) Raum.
leg_d = {}
sampled_points.startEditing()
for h in legend.getFeatures(): #iterating rgb values from legend
fieldname = f'dist_{h[cat_id]}'
leg_d[fieldname] = h[type_description] #fills the dict
addFields([fieldname], sampled_points)
ref_rgb = [h[g] for g in leg_rgb_idx]
for i in sampled_points.getFeatures():
rgb = ['band_1', 'band_2','band_3'] #default prefix qgis randompointsinpolygons
rgb_idx = [getFIdx(i, sampled_points) for i in rgb]
ed = euclidean_distance([i[j] for j in rgb_idx], ref_rgb)
if ed < ed_threshold:
i.setAttribute(fieldname,ed)
sampled_points.updateFeature(i)
sampled_points.commitChanges()Der Programmschnippsel aus dem Klassifikationsskript oben dient zur Distanzberechnung zwischen jeden RGB-Wert und jedem Referenzwert. Je geringer die Distanz, desto eher lässt sich der jeweilige Punkt klassifizieren. An Hand des unique identifiers der Referenzgeometrie lassen sich diese Distanzwertezusammenfassen und in Kombination mit ihrem jeweiligen Anteil an der Gesamtanzahl der Punkte pro Referenzgeometrie ergibt sich die Wahrscheinlichkeit welcher Klasse (der Kartenlegende) eine Geometrie angehört.
Im kompletten Workflow ergibt sich damit ein iterativer Aspekt, der es erlaubt, bei nicht eindeutiger Zuordnung, eine stets kleiner werdende Anzahl von Referenzgeometrien nocheinmal über den gezeigten Weg zu klassifizieren - wobei bei jedem Durchgang der vorhing erwähne Negativ-Buffer, sowie die Punktdichte vergrößert werden. (siehe strichlierte Linie im Flowchart unten).