
Förderjahr 2023 / Stipendien Call #18 / ProjektID: 6801 / Projekt: Communication and Energy Efficient Edge Artificial Intelligence Framework for Internet of Things
This is an introductory blog on distributed machine learning, with a particular focus on federated learning. We delve into the motivation driving federated learning, its huge potential, and discuss its inherent limitations.
Proliferation of the IoT devices has led to an increased amount of data being produced at the edge of the network. The traditional approach of transporting vast volumes of data from these distributed IoT devices to a central server presents several challenges. Firstly, it places immense strain on communication infrastructure, leading to network congestion and latency issues. For time-critical applications such as eHealth, autonomous vehicles, and environmental monitoring, where even minor delays can have significant consequences for decision-making. Secondly, it might expose the users private data and compromise their privacy. This concern is especially critical for applications such as healthcare and personal finance.
Federated Learning (FL) first introduced by Google, offers a promising solution to overcome these challenges. By decentralizing the training process and conducting model updates locally on the IoT device, FL minimizes the need for raw data transmission to the central server. FL not only reduces the communication overhead but also addresses privacy concerns by ensuring that sensitive data remains on user's devices.
FL for Disease Prediction
Consider a scenario in which multiple hospitals collaborate to develop an ML model for predicting the risk of a certain medical condition (e.g., diabetes) in patients. However, due to privacy regulations (GDPR) and ethical considerations, sharing patient data among hospitals is not feasible.
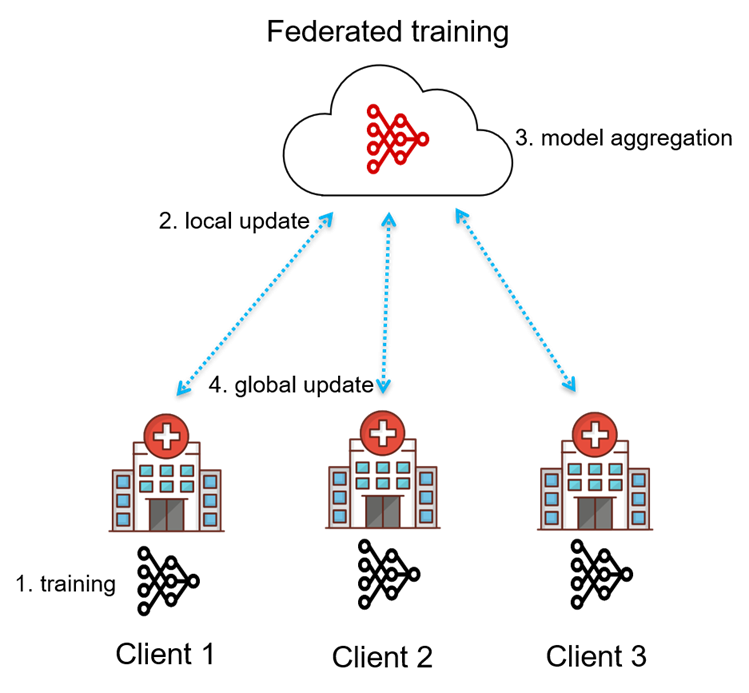
- Each client (hospital) independently trains a model using its local patient data. During local training, clients compute model gradients based on their data while preserving privacy by not sharing their training data.
- After computing the local updates, each client transmits the local update to the parameter server (cloud).
- Once the parameter server has received updates from all the clients, it performs aggregation to compute the global model update.
- The parameter server broadcasts the updated global modal back to the clients for the next training iteration.
Challenges: While FL has numerous advantages there are certain shortcomings that need to be addressed;
- Frequent communication between the clients and the parameter server can result in communication overhead.
- Data heterogeneity which is the case in most real-world applications deteriorates the performance of the global model significantly.
- FL aims to preserve privacy by keeping data private, however, there are still potential privacy risks.
- Similar to data heterogeneity, system heterogeneity can restrict the participation of certain clients due to resource (e.g., memory or computation) imbalance.

