
Förderjahr 2020 / Stipendien Call #15 / ProjektID: 5115 / Projekt: Improving Serverless Edge Computing for Network Bound Workloads
In diesem Blogpost möchte ich auf etwas eingehen, was mich bei meiner Diplomarbeit unerwartet große Mengen an Zeit gekostet, aber gleichzeitig unerwartet interessante Ergebnisse hervor gebracht hat: Die Implementierungsdetails von Load Balancern. Als kurze wiederholung, oder Einführung für Leute außerhalb des Fachbereichs will ich hier kurz beschreiben was ein load balancer denn eigentlich ist und tut. Wie man dem Namen entnehmen kann ist es eine Komponente, welche Last verteilt. Konkret geht es hierbei um Web-Basierte load balancer, also jene die Web-Anfragen auf Server verteilen. Sobald eine Website oder ein Service so viele Anfragen bekommen, dass ein einzelner Server diese nicht alleine handhaben kann werden Load Balancer essentiell um diese Last auf mehrere Server zu verteilen. Weil Server, Anfragen, Netzwerke und andere Gegebenheiten sich stark voneinander unterscheiden können gibt es unterschiedliche Techniken Load Balancing zu betreiben. Die einfachste, und wohl bekannteste, heißt “Round Robin”. Diese verteilt die eingehenden Anfragen gleich auf die vorhandenen Server. Alle Server werden gleich belastet. Diese Technik ist bis heute die wohl meistgenutzte, aber es gibt Situationen in denen diese Methode unpassend ist. Edge Computing ist ein klassisches Beispiel hierfür: Server können sich in ihrer Rechenleistung massiv unterscheiden und auch die Netzwerkdistanzen variieren stark. Vereinfacht gesprochen: Es macht keinen Sinn eine Anfrage ans andere Ende der Welt zu senden, wenn denn um die Ecke auch ein passender Server steht. Diese Thematik habe ich bereits in einem anderen Blogpost beschrieben. Wie im anderen Blogpost beschrieben ist Least Response Time eine robuste und erprobte Methode in Edge-Computing Szenarien bessere Ergebnisse zu erziehen, weil Anfragen an jene Server gesendet werden, die vermutlich am schnellsten antworten, wodurch Faktoren wie die Netzwerkdistanz oder Rechenleistung implizit berücksichtigt werden. In meiner Implementierung und Adaptierung von Least Response Time werden den Servern Gewichte zugeordnet, und die Last anhand dessen verteilt. Je höher das Gewicht, desto mehr Last bekommt ein Server. Diese Load Balancing Technik ist ebenfalls wohlbekannt und wird Weighted Round Robin genannt. Für meine Herangehensweise verwende ich eine Kombination aus Least Response Time und Weighted Round Robin. Die Basis der Load Balancing Entscheidungen ist Weighted Round Robin, wobei die Gewichte selbst auf Basis der Antwortgeschwindigkeit (Response Time / RT) gewählt werden. Wie genau das passiert werde ich im nachfolgenden Blogpost beschreiben, da das hier den Rahmen sprengen würde. Worum es hier weiter geht ist wie die genaue Implementierung, also die Umsetzung im Code, eines solchen Load Balancing Algorithmus das System beeinflust. Naiv angenommen sollte man meinen es gibt hier keine wesentlichen Unterschiede: Man trifft eine Auswahl zwischen verschiedenen Servern, und wie häufig welcher gewählt wird soll linear proportional zum Gewicht sein. Hierzu habe ich ein Experiment durchgeführt. In meiner Simulationsumgebung werden unterschiedliche Implementierungen miteinander verglichen. Nachdem es sich um ein dynamisches System handelt werden die Gewichte in fixen Zeitintervallen angepasst. Ohne hier zu sehr ins Detail zu gehen (das können Interessierte der fertigen Arbeit entnehmen) zeigen die Ergebnisse, dass die Unterschiede dramatisch ausfallen können. Im folgenden Graph sieht man drei Implementierungsmethoden für Weighted Round Robin sowie eine vierte die zum Vergleich herangezogen wird. Kurz beschrieben sind diese:
- Random: Eine Vergleichsimplementierung, welche die Entscheidungen rein zufällig (aber den Gewichten entsprechend) trifft. Die Gewichte repräsentieren hier die Wahrscheinlichkeiten in einem sonst zufälligen System
- Classic: Eine klassiche und bekannte, rein deterministische Implementierung in welcher die Server absteigend nach ihrem Gewicht gewählt werden. Wurden alle Server abgearbeitet startet die Prozedur von neuem. Hier ist eine Pseudocode-Implementierung zu finden: http://kb.linuxvirtualserver.org/wiki/Weighted_Round-Robin_Scheduling
- Adapted Classic: Die gleiche Implementierung wie Classic, jedoch wurde sie angepasst um die Gewichte während der Laufzeit ändern zu können, ohne dass der Algorithmus dabei neu gestartet werden muss
- Smooth: Eine andere Methode, welche ebenfalls vollkommen deterministisch funktioniert, aber die Reihenfolge der Server nicht durch das Gewicht bestimmt. Das Ergebnis ist dasselbe als würde man aus “Classic” viele Samples ziehen und diese dann mischen.
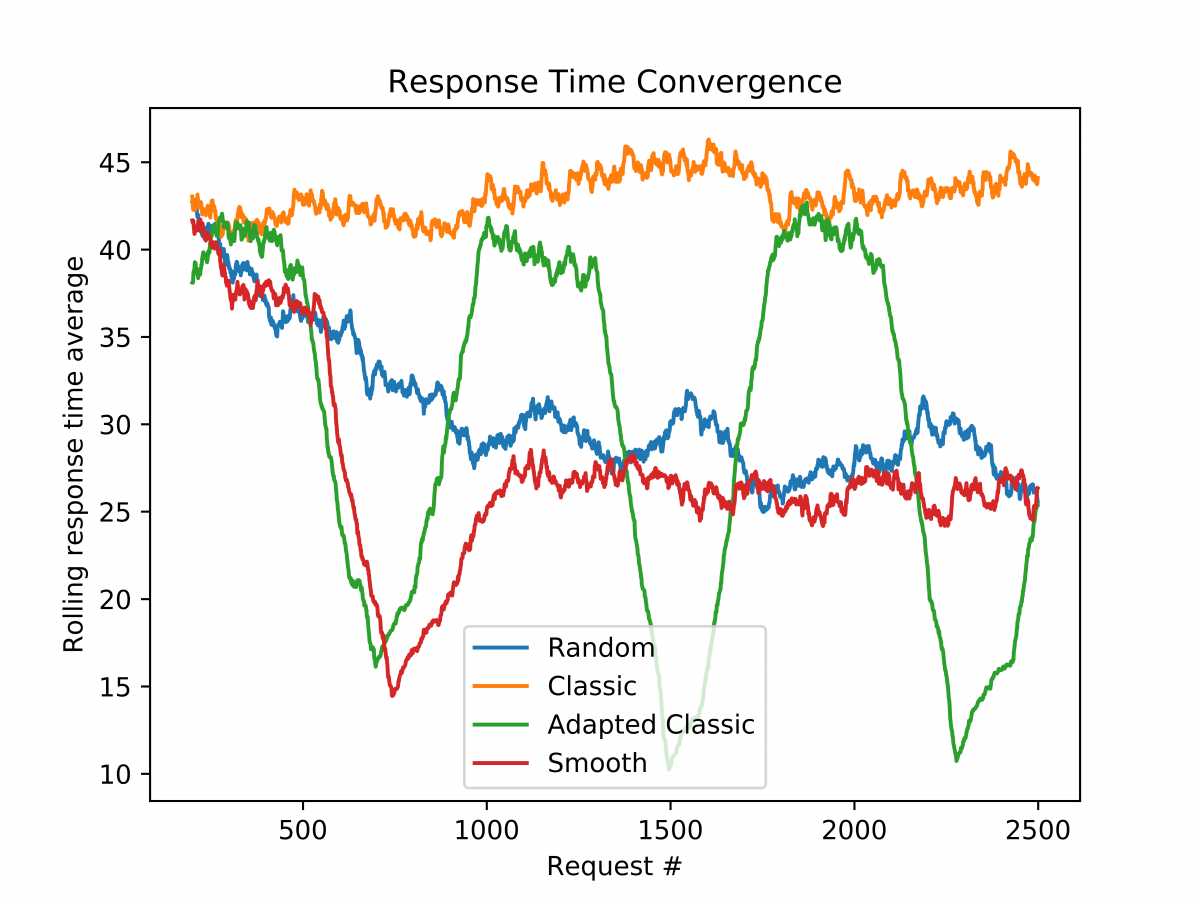
Der Graph zeigt wesentliche Unterschiede zwischen den Implementierungen. Die Zufällige Auswahl und die Klassische Implementierung sind im Wesentlichen ungeeignet, wohingegen Smooth und Adapted Classic deutlich bessere Performance bieten. Für meine Herangehensweise habe ich mich für Smooth entschieden, wobei Classic uns einen spannenden Blick in die Zukunft zeigt: Je nach Bedarf angepasste Serverauswahlen für unterschiedliche Clients, oder Arten an Requests.
Die Ergebnisse unterstreichen weshalb bestehende Techniken nicht unverändert in Edge-Computing Szenarien funktionieren, aber auch welche neuen Techniken dadurch ermöglicht werden.
