
Förderjahr 2020 / Stipendien Call #15 / ProjektID: 5115 / Projekt: Improving Serverless Edge Computing for Network Bound Workloads
Nach ersten Versuchen und frühen Experimenten hat sich sehr schnell herausgestell, dass effizientes Routing von Requests eines der zentralen Probleme ist, die für die Verbesserung der Performance bei Network Bound Workloads gelöst bzw. verbessert werden müssen.
Um hier etwas besseres Verständnis zu bieten sehen wir uns folgendes Diagramm an:
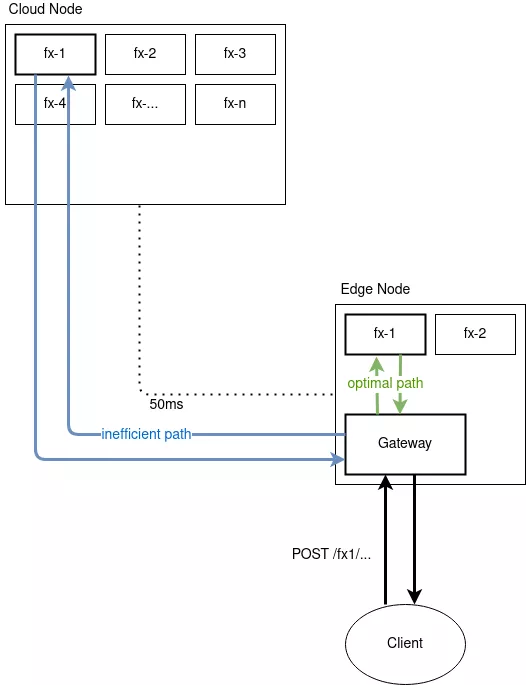
Wir sehen eine Node, sprich einen Server, an der “Edge” des Netzwerks, also nahe am Endgerät der Benutzer*in, und eine weitere Node in der Cloud, also weiter entfernt. In der Architektur von typischen Serverless Systemen wie z.B. OpenFaaS existieren verschiedene Komponenten welche gemeinsam das System darstellen. Diese “laufen” jeweils auf Nodes. Eine solche Komponente kann auf einzelnen oder mehrfach auf unterschiedlichen Nodes laufen. Für Erklärungszwecke unterscheiden wir zwischen zwei Arten an Komponenten: Funktionen und dem Gateway. Funktionen sind der Code der bei einer Anfrage ausgeführt wird, das “F” in “FaaS”. Der Gatway ist der “Eingangspunkt” für Requests. Alle Requests kommen zuerst an den Gateway und dieser leitet diese dann an die entsprechende Funktion weiter.
Hier sehen wir recht schnell das erste Problem. Nehmen wir an wir sind in einem System wie dem im Diagramm sichtbaren. Die Anfrage an Funktion 1 (fx-1) könnte von der Edge-Node sowie von der Cloud-Node bearbeitet werden, weil die Funktion auf beiden aktiv ist. Der Gateway ist ebenfalls auf der Edge Node und damit nahe am Endgerät. Wenn der Gateway nun den Request an die Funktion auf der Cloud-Node weiterleitet wird der Request über eine unnötig lange Strecke im Netzwerk gesendet, wodurch die Verzögerung sich vergrößert. Die andere Richtung wäre auch denkbar: Möglicherweise ist die Edge Node nicht sehr leistungsfähig, die Cloud Node aber schon. In diesem Fall könnte es Sinn machen trotz der längeren Übertragungszeit den Request an die Cloud zu senden. Es ist also recht schnell klar, dass die Routing Entscheidung die der Gateway treffen muss nicht trivial ist.
Hiermit sind wir am ersten Problem angelangt: Um die Performance von Serverless Edge Computing zu verbessern ist es notwendig bessere Routing Entscheidungen zu treffen.
Anpassung von Traefik
Traefik ist ein Open Source Edge Router, vergleichbar mit nginx, allerdings mit deutlich moderneren Features. Sobald klar war, dass eine Form von intelligentem load-balancing passieren muss, und das theoretische Konzept da war, stellte sich die Frage wie diese Änderungen in praktischen Experimenten evaluiert werden können. Der Gateway von OpenFaaS verfügt standardmäßig nur über round-robin load-balancing (hierbei werden die verfügbaren server einfach gleichmäßig abgewechselt), beziehungsweise gibt der Gateway load-balancing Entscheidungen an die Umgebung (z.B. Kubernetes) ab, die selbst wiederum meistens nur round-robin unterstützen. In Cloud Szenarien ist dies meistens auch ausreichend da das Netzwerk stabil, und die Ressourcen homogen sind, aber bei Edge Computing ist dies schlicht nicht der Fall.
Es gibt keinen Grund wieso das experimentelle load-balancing direkt im Gateway implementiert werden müsste, weshalb die Entscheidung gefallen ist dies stattdessen in einer separaten Komponente zu realisieren. Daher wurde Traefik angepasst um die Art von komplexem und dynamischem load-balancing zu unterstützen, die für die Experimente benötigt wird.
Neben einem System um beliebig viele Metriken hinzuzufügen, wurde least-response-time als exemplarische Beispielmetrik implementiert. Der Vorteil hiervon: Die angepasste Version von traefik ist auch außerhalb des Serverless oder Edge Computing Kontexts nützlich. Der source code ist selbstständlich open source und findet sich hier: https://github.com/jjnp/traefik/tree/load-balancing Eventuell werden diese Änderungen dauerthaft in traefik integriert, aber davor bedarf es noch etwas feinschliff, und selbstverständlich der Zustimmung der Entwickler*innen von traefik.
In umfangreichen Tests um die load-balancing Kapazität von traefik zu prüfen war bereits ersichtlich, dass least-response-time bessere und konsistentere Performance bietet als round-robin. Ein großer Vorteil an lowest-response-time ist, dass keine externen Metriken notwendig sind, sprich keine Informationen über die Prozessorauslastung von Nodes oder vergleichbares, was eventuell schwer verfügbar ist. Ein hohes Maß an Informatiton wie die Auslastung, und Netzwerkdistanz sind implizit in die response-time integriert, wodurch es eine ausgezeichnete und vor allem einfache proxy-Metrik darstellt.
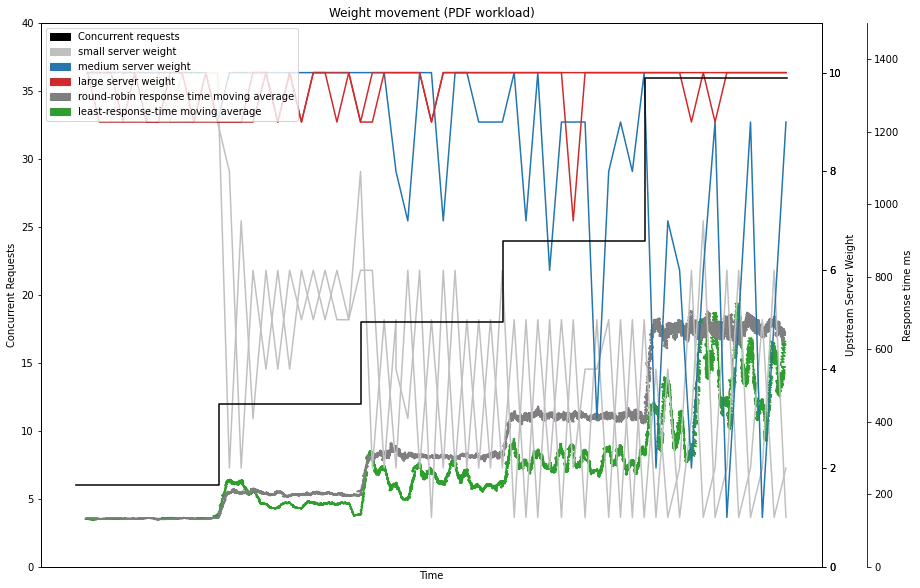
Für die weiteren Experimente, welche konkret im Serverless Bereich sind ist geplant weitere Metriken neben der response-time zu integrieren. Hier besteht eine gewisse Diskrepanz zwischen den Daten, welche für eine mathematisch optimale Entscheidung notwendig wären, und jenen die in der Praxis verfügbar sind. Das Ziel ist eine möglichst nahe und praktisch umsetzbare Heuristik für die “optimale” mathematische Funktion zu finden.
