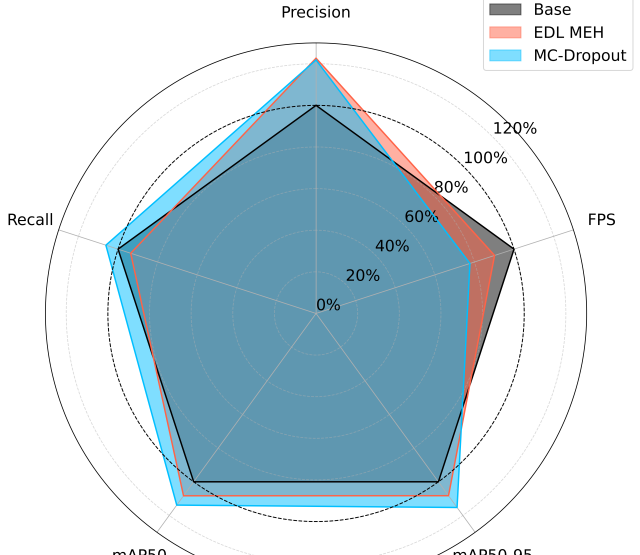
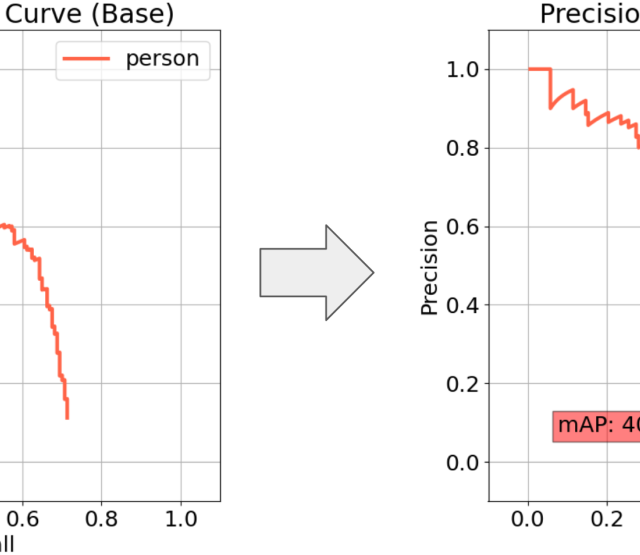
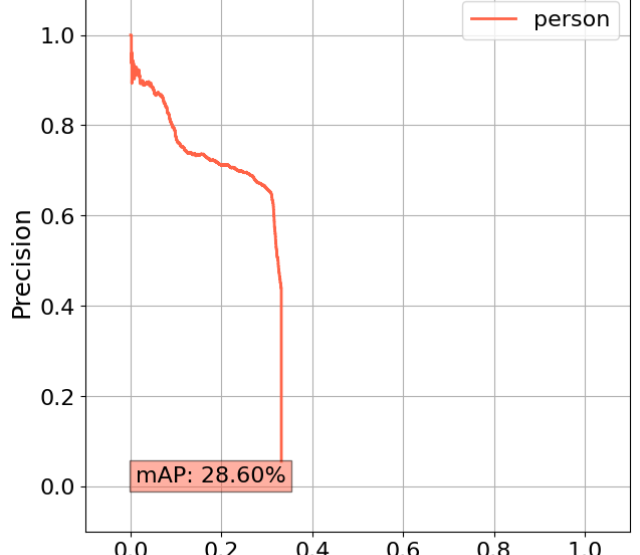
Förderjahr 2023 / Stipendien Call #18 / ProjektID: 6885 / Projekt: Increasing Trustworthiness of Edge AI by Adding Uncertainty Estimation to Object Detection
Object detection models typically do not capture the whole uncertainty in their predictions. It is important to first know what types of uncertainty there are, how they can be estimated, and what the impact on computational resources is.
Different Kinds of Uncertainty
Regarding uncertainty, Senge et al. [7] break it down into two types: aleatoric and epistemic. Aleatoric uncertainty, also known as statistical uncertainty, is due to randomness that will not change no matter how much extra data is used for training. On the flip side, epistemic uncertainty, or systematic uncertainty, is the part that can be trimmed down with more knowledge, i.e., by having more training data.
Why does this matter? Aleatoric uncertainty can be captured using categorical distributions, such as the commonly used Softmax function [3]. So essentially, this type of uncertainty is easy to measure and already represented by the classification scores of typical object detection models. However, these standard methods usually do not tell anything about the epistemic uncertainty in the model itself [3]. So, for estimating the overall uncertainty (aleatoric+epistemic), some extra work is required.
Figuring Out Uncertainty
To capture both aleatoric and epistemic uncertainty, Bayesian neural networks offer the necessary probabilistic tools. The probabilistic network can be approximated by using the Dropout technique [2], which also helps to mitigate overfitting [9]. Another method is Ensembling, where multiple models are trained independently, with different base settings and individually shuffled training data, so they end up with different parameters [6].
However, both Dropout and Ensembling methods have a downside, their increase in computational complexity. Multiple forward passes or running the same input on different models means they are not well suited for real-time applications on resource-constrained devices [3].
Sensoy et al. [8] introduced Evidential Deep Learning (EDL) for classification as an alternative to the traditional costly uncertainty estimation methods. EDL uses subjective logic and evidence theory to teach the network the parameters of a Dirichlet distribution during training. This helps the model express uncertainty in predictions when faced with unseen data. Similarly, EDL for regression allows for uncertainty estimation for continuous predictions too [1].
Modification of Object Detection Models
Object detection models can be implemented as two-stage or one-stage detectors [4], where one-stage models are generally faster, and therefore, also preferred for this work’s application in an Edge environment.
One popular one-stage model is the Single Shot MultiBox Detector (SSD), as presented by Liu et al. [5]. The model uses convolutional layers to create different-sized feature maps, helping it spot objects at various sizes and positions in an image in one forward pass. It starts with detailed maps to catch small features and gradually gets coarser later in the network, ending with a 1x1 size to represent the whole image. This way, it can detect everything from small to big objects, as shown below in the architectural overview image [5].
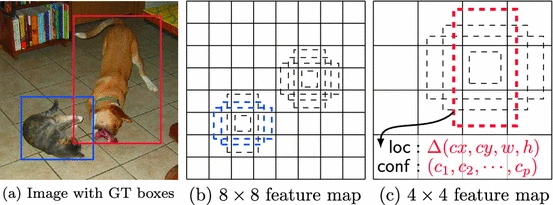
Every cell in every feature map gets its detector, each predicting 4 bounding box coordinates and N + 1 classification scores. N is the number of classes present in the image, plus an extra class for background detections when no object is around.
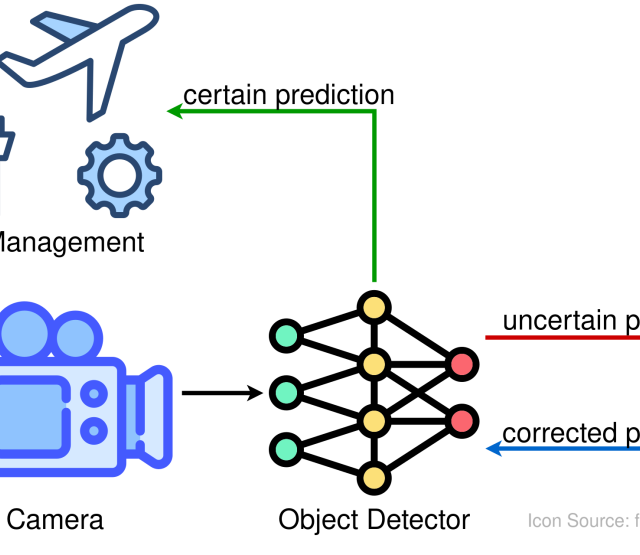
The chosen way of adding uncertainty estimation to the SSD model here will be by using Evidential Deep Learning, where EDL for classification [8] can predict uncertainties for class labels, and EDL for regression [1] can estimate uncertainties of bounding box coordinates. Therefore, the next goal will be to implement EDL by modifying a regular SSD model and evaluating the resulting performance. A simplified example mockup of such modifications (regular prediction on the left, uncertainty estimation on the right) can be seen in the figure down below, where the model trained to detect persons marks pedestrians with low uncertainty (green), and other objects mistakenly identified as persons with high uncertainty (red).

References
[1] Alexander Amini, Wilko Schwarting, Ava Soleimany, and Daniela Rus. Deep evidential regression. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 14927–14937. Curran Associates, Inc., 2020.
[2] Yarin Gal and Zoubin Ghahramani. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. In international conference on machine learning, pages 1050–1059. PMLR, 2016.
[3] Fredrik K Gustafsson, Martin Danelljan, and Thomas B Schon. Evaluating scalable Bayesian deep learning methods for robust computer vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 318–319, 2020.
[4] Yali Amit, Pedro Felzenszwalb, and Ross Girshick. Object detection. Computer Vision: A Reference Guide, pages 1–9, 2020.
[5] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In European conference on computer vision, pages 21–37. Springer, 2016.
[6] Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. In Proceedings of the 31st International Conference on Neural Information Processing Systems, pages 6405–6416, 2017.
[7] Robin Senge, Stefan Bösner, Krzysztof Dembczynski, Jörg Haasenritter, Oliver Hirsch, Norbert Donner-Banzhoff, and Eyke Hüllermeier. Reliable classification: Learning classifiers that distinguish aleatoric and epistemic uncertainty. Information Sciences, 255:16–29, 2014.
[8] Murat Sensoy, Lance Kaplan, and Melih Kandemir. Evidential deep learning to quantify classification uncertainty. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, pages 3183–3193, 2018.
[9] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1):1929–1958, 2014.
[10] Ben Benfold and I. Reid. Stable multi-target tracking in real-time surveillance video. CVPR 2011, pages 3457–3464, 2011.