
Förderjahr 2017 / Project Call #12 / ProjektID: 2116 / Projekt: ContractVis
Während wir visuellen Darstellungen von Zahlenverhältnissen (z.B. Wahlergebnisse als Balkendiagramm) oder Zeitreihen (z.B. Tageshöchsttemperatur als Liniendiagramm) oft in Zeitungen oder anderen Medien begegnen können, sind visuelle Darstellungen von Text weniger naheliegend – außer natürlich den Text komplett hinzuschreiben. Durch die geschickte Kombination von Algorithmen und Visualisierungen lassen sich relevante Information auch aus langen Texten kompakt darstellen und können je nach Interesse gezielt weiter erforscht werden.
Im folgenden Blogpost sollen einige solche visuellen Textanalyse Werkzeuge vorgestellt werden.
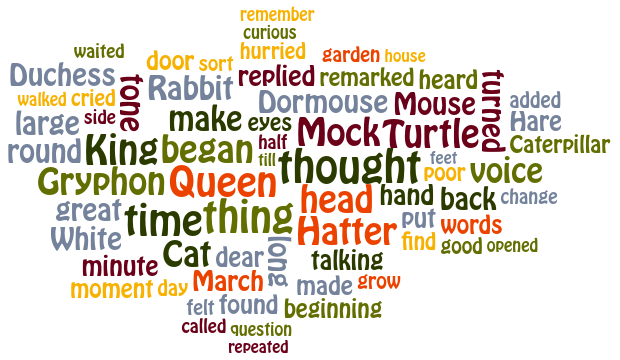
Word Clouds fassen einen Text zusammen, indem sie die häufigsten Wörter in absteigender Schriftgröße darstellen. Diese Wörter werden so platziert, dass sich ein auf Kompaktheit optimiertes Layout ergibt, das oft auch ästhetisch ansprechend ist. Eine Einschränkung von Word Clouds ist, dass der visuelle Vergleich zwischen zwei Wort Clouds nicht leicht möglich ist, weil selbst geringe Änderungen am Text ein komplett anderes Layout ergeben können.
Online Tool: z.B. http://www.edwordle.net/
Referenz: Viégas, F. B., & Wattenberg, M. (2008). Tag Clouds and the Case for Vernacular Visualization. Interactions, 15(4), 49–52. https://doi.org/10.1145/1374489.1374501

Ein Word Tree zeigt alle Textpassagen in denen ein gesuchtes Stichwort (im Bild “mouse”) vorkommt und stellt diese als einen Baum dar. So werden alle Passagen zusammengefasst, in denen das nächste bzw. übernächste Wort dasselbe ist. Im Bild sieht man oben alle Passagen, in denen “mouse, who” vorkommt. Rechts im Bild können wir drei Sätze mit dem Stichwort im Detail lesen. Die Leiste in der Mitte zeigt, wo im gesamten Text das Stichwort vorkommt.
Online Tool: https://www.jasondavies.com/wordtree/
Referenz: Wattenberg, M., & Viegas, F. B. (2008). The Word Tree, an Interactive Visual Concordance. IEEE Transactions on Visualization and Computer Graphics, 14(6), 1221–1228. https://doi.org/10.1109/TVCG.2008.172
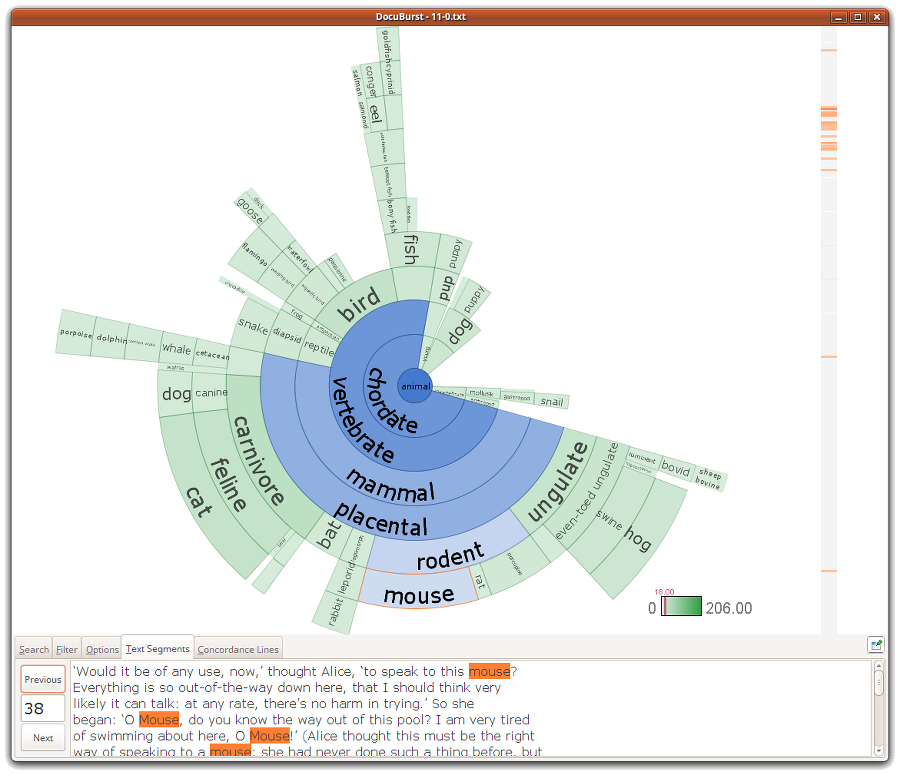
Auch DocuBurst starten wir mit einem Stichwort. Daraufhin wird der Text nach Unterbegriffen (Hyponyme) dieses Stichwortes durchsucht. Beispielsweise finden wir bei der Suche nach “animal” die Tiere “mouse”, “cat” oder “goldfish”. Diese Hierarchie von Begriffen wird in einer sogenannten Sunburst Visualisierung dargestellt. Im Bild wurde “mouse” ausgewählt und wir sehen rechts in der Leiste, die Stellen wo dieses Wort vorkommt. Die Box unten zeigt eine dieser Stellen im Detail, sodass der Begriff im Kontext steht.
Desktop Tool: https://github.com/vialab/docuburst-desktop/
Referenz: Collins, C., Carpendale, S., & Penn, G. (2009). DocuBurst: Visualizing Document Content using Language Structure. Computer Graphics Forum, 28(3), 1039–1046. https://doi.org/10.1111/j.1467-8659.2009.01439.x
VarifocalReader ist ein Forschungsprototyp der Universität Stuttgart, der speziell für die Analyse historischer Bücher entwickelt wurde. Dazu werden Zusammenfassung des Textes auf mehreren Ebenen wie Kapitel, Absätze oder Zeilen als Word Cloud oder Balkendiagramm dargestellt. Von links nach rechts rückt der Fokus immer mehr zum Detail - bis hin zu Scans der Seiten aus den Originalbüchern.
Website: http://epoetics.visus.uni-stuttgart.de/
Referenz: Koch, S., John, M., Wörner, M., Müller, A., & Ertl, T. (2014). VarifocalReader: In-Depth Visual Analysis of Large Text Documents. IEEE Transactions on Visualization and Computer Graphics, 20(12), 1723–1732. https://doi.org/10.1109/TVCG.2014.2346677
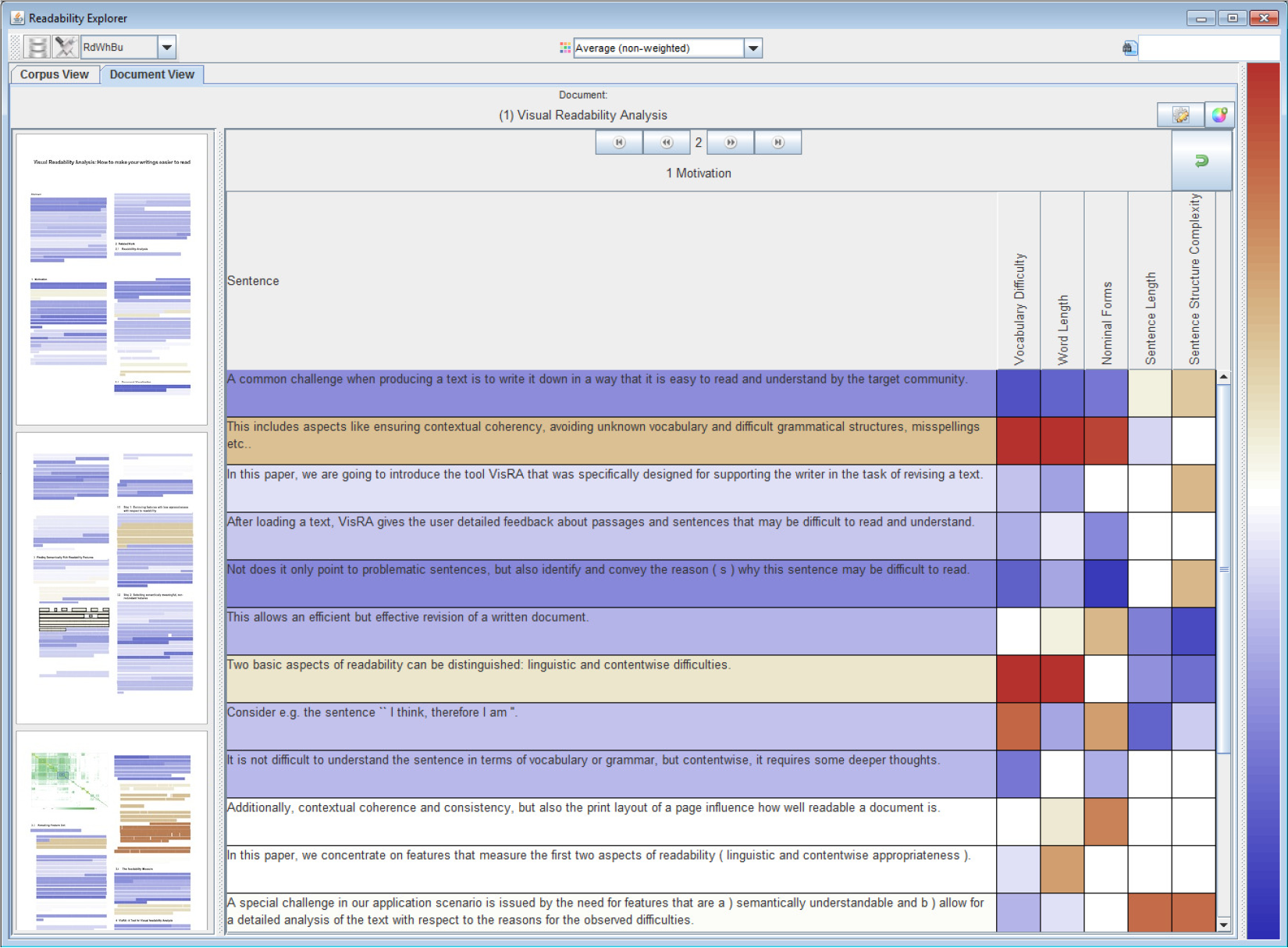
Die Visual Readability Analysis der Universität Konstanz ist ein Forschungsprototyp, der Autoren unterstützen soll ihre Texte gezielt auf bessere Lesbarkeit hin zu überarbeiten. Dazu werden pro Satz verschiedene Kennzahlen wie Komplexität des Vokabulars und Satzlänge berechnet und mittels Farbkodierung (blau für leicht lesbar bis rot für schwer lesbar) dargestellt (vgl. Bild).
Website: https://www.vis.uni-konstanz.de/forschung/text/age-suitability-and-readability-analysis/
Referenz: Oelke, D., Spretke, D., Stoffel, A., & Keim, D. A. (2012). Visual Readability Analysis: How to Make Your Writings Easier to Read. IEEE Transactions on Visualization and Computer Graphics, 18(5), 662–674. https://doi.org/10.1109/TVCG.2011.266
Diese Auswahl von Methoden und Beispielen zur visuellen Textanalyse zeigt Möglichkeiten auf, wie wir in ContractVis Vertragstexte aufbereiten könnten. Mehr dazu in den folgenden Blogposts.
Für alle, die zu Ende gelesen haben, gibt es noch eine Gewinnfrage: Der Text welchen Buches wurde in den ersten drei Bildern analysiert? Für die erste richtige Antwort (per NetIdee / Twitter / Email) gibt es eine Flasche Traubensaft vom Weingut Roch (abzuholen in St. Pölten).







