
Förderjahr 2023 / Projekt Call #18 / ProjektID: 6745 / Projekt: weBIGeo
Es gibt verschiedene Paradigmen wie interaktive Geovisualisierung im Browser technisch umgesetzt werden kann. Um sich für ein Paradigma zu entscheiden, muss man die Lösung in Hinblick auf zwei wichtige Aspekte untersuchen: 1) Geschwindigkeit der interaktiven Anwendung und 2) die Datenmengen, die der Client speichern und verarbeiten muss. Es hängt dann von den Daten, den verwendeten Endgeräten, dem verfügbaren Server, der Anzahl der antizipierten Benutzer_innen, der gewünschten Interaktivität, sowie der Internetverbindung ab, welches Paradigma am besten für die gewünschte Anwendung geeignet ist.
Wir bieten hier eine Entscheidungshilfe:
Offline Preprocessing: Tiles
Wie bereits in einem früheren Blogpost erläutert, gibt es immer die Möglichkeit Datenoverlays vorzuberechnen und in einer Level-of-Detail Struktur von gerasterten Bildern – sogenannte Tiles – abzuspeichern. Das ist immer dann besonders sinnvoll, wenn die Daten selbst groß sind und sich nicht ändern. Der Vorteil von Tiles ist, dass der Client sehr gezielt Daten in verschiedenen Detailstufen anfordern kann und damit die Datenmenge kontrollieren kann. Auch schwache Clients können damit die Datenmenge gering halten indem sie nicht so detaillierte Overlays vom Server anfordern. Wenn die Tiles aus sehr großen Daten generiert wurden, kann der Speicherbedarf im Vergleich zu den Rohdaten am Server mitunter sogar sinken.
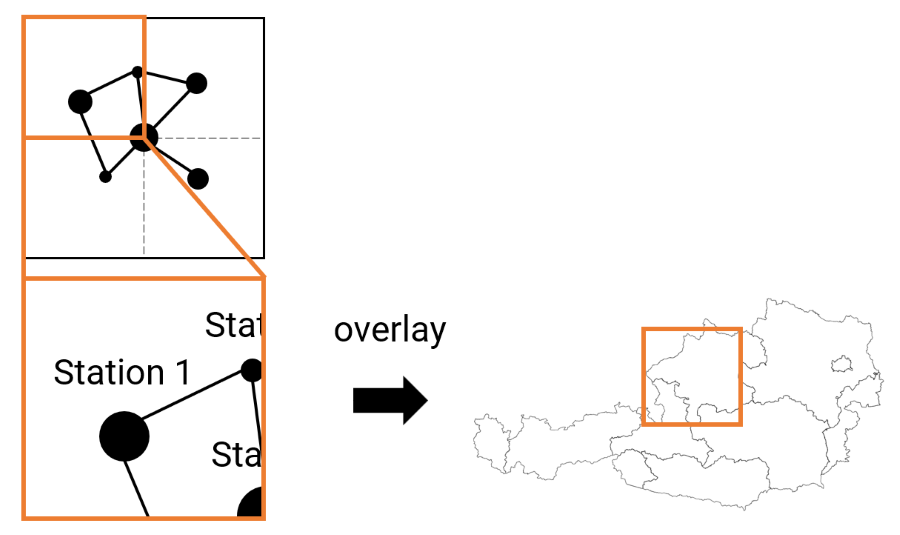
Beim Offline Preprocessing Paradigma werden Bildpyramiden (sogenannte Tiles), die die Daten darstellen, am Server vorgeneriert und zur Laufzeit in der benötigten Detailstufe vom Client abgefragt. Der Client blendet dann die darunterliegenden Karten mit dem Datenoverlay.
Der Nachteil von Tiles ist, dass die Datenmenge, die auf einem Server gespeichert werden muss, immer hoch ist, auch wenn die Rohdaten klein sind. Im schlimmsten Fall übersteigt der Speicherbedarf der Tile-Daten den der Rohdaten um ein Vielfaches. Zusätzlich kann auch das Streamen der Tiles ein Bottleneck sein, wenn verschiedene Daten miteinander verknüpft werden müssen. Der größte Nachteil von Tiles ist jedoch, dass sie bei jeder Änderung der darunterliegenden Daten neu berechnet werden müssen, was viel Zeit kosten kann. Aber auch wenn sich nur die Darstellung selbst ändern soll, müssen alle Tiles neu generiert werden. Anstelle von vorberechneten Bildern (sogenannte Raster Tiles) bieten Vector Tiles ein bisschen mehr Flexibilität bei der Darstellung. Die räumliche Platzierung der Informationen ist aber in jedem Fall vordefiniert.
Zusammenfassend kann man sagen, dass eine offline Erstellung von Tiles immer dann sinnvoll ist, wenn die darunterliegenden Daten sehr groß sind, sich selten (oder gar nie) ändern, und eine eindeutige räumliche Position haben. Typische Beispiele sind Straßenkarten und Höhendaten, aber auch in der Vergangenheit gemessene Sensordaten.
Server-Side Analysis & Rendering
In dem Paradigma werden die Bilder, die beim Client angezeigt werden, direkt am Server gerendert und als fertige Bilder an den Client geschickt. Der Client selbst kümmert sich nur mehr um den User-Input und das Darstellen des übermittelten Bildes. Der Client muss auch nicht zwangsweise Daten (zwischen)speichern. Damit ist die Anwendung größtenteils unabhängig von den Hardware-Ressourcen (Speicher, CPU, GPU) des Clients. Die Größe der Daten, die gesendet werden, hängen von der Interaktionshäufigkeit und der Bildschirmgröße des Clients ab, nicht jedoch von der Anzahl und Größe der Rohdaten.
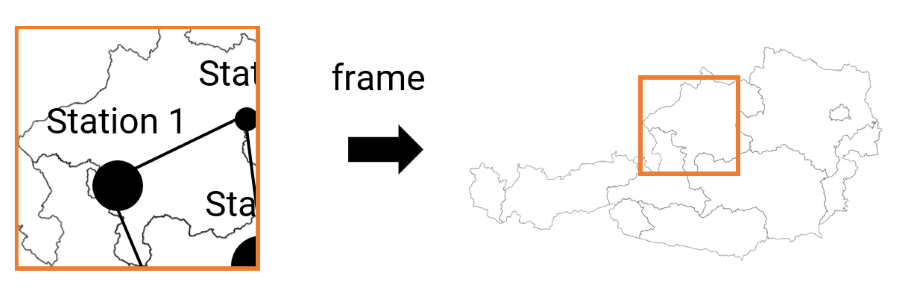
Server-Side Analysis & Rendering: Die Karte wird gemeinsam mit den darzustellenden Daten am Server zur Laufzeit generiert und als fertige Bilder an den Client verschickt.
Der Nachteil ist, dass der Server mit vielen gleichzeitigen Zugriffen zurechtkommen muss. Je nach Anwendung muss der Server also außergewöhnlich leistungsstark für das Rendering sein. Anwendungen, die sehr viel Interaktivität bieten, benötigen außerdem eine sehr hohe Bandbreite, da ständig neue Bilder an den Client geschickt werden können. In vielen Fällen wird es nicht möglich sein, einen flüssigen Stream mit mindestens 30 FPS zu erzeugen, sodass die Anwendung für die Nutzer_innen merkbare Latenzen aufweisen wird. Das flüssige Fliegen durch 3D Landschaften könnte schon zu großen Schwierigkeiten führen.
Server-Side Rendering ist also vor allem für Anwendungen sinnvoll, auf die selten und von wenigen Nutzer_innen gleichzeitig zugegriffen wird. Insbesondere ist es dann vorteilhaft, wenn die Daten aufwändig zur Laufzeit verarbeitet werden müssen, der Server entsprechende Kapazitäten aufweist und die Internetverbindung sehr gut ist. Frameworks zur Visualisierung von sehr großen wissenschaftlichen Daten, wie etwa ParaView, bieten daher Server-Side Rendering als Standard-Paradigma an. Auch Cloud Gaming Plattformen bieten gegen Bezahlung Server-Side Rendering von Spielen in Data Centers an und streamen die Bilder an die Clients. Je nach gewünschter Bildqualität ist eine hohe Bandbreite (50 Mbit/s) nötig.
Client-Side Analysis & Rendering
Da selbst mobile Endgeräte immer leistungsstärker werden, ist Client-Side Rendering eine immer attraktivere Lösung für interaktive online Visualisierung. Client-Side Rendering ist unabhängig von anderen Nutzer_innen und der Serverinfrastruktur. Es kann auch aktuelle Daten anfragen, mehrere Datenquellen verknüpfen und je nach Belieben der Nutzer_innen auswerten und anzeigen. Es bietet also von allen Paradigmen die größte Flexibilität.
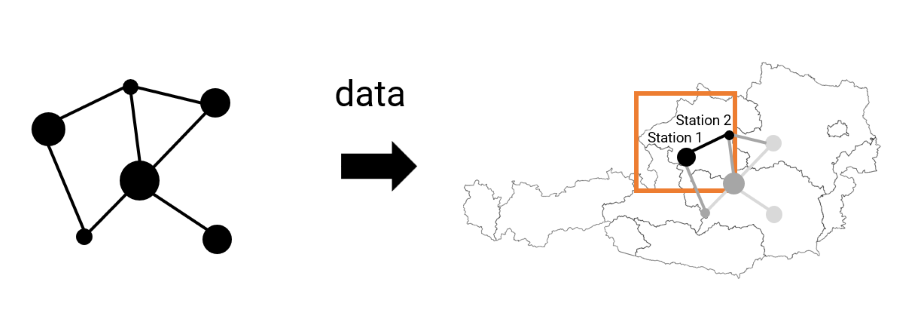
Client-Side Analysis & Rendering: Der Client lädt die gesamten benötigten Rohdaten von einem Server und kümmert sich selbst um die korrekte Darstellung.
Der größte Nachteil ist natürlich, dass diese Lösung gänzlich von den Ressourcen des Clients abhängig ist. Einerseits kann die Grafikkarte des (mobilen) Endgerätes zu schwach für Echtzeit-Analyse und Rendering sein. Andererseits kann der (Browser-)Speicher ein limitierender Faktor sein, da nicht alle anzuzeigenden Daten gespeichert werden können. Schließlich kann natürlich auch eine limitierte Bandbreite den Flaschenhals darstellen, da das Herunterladen von sehr großen Daten auch entsprechend lange dauern kann. Kritische Anwendungen sollten daher auch immer eine Fallback-Lösung mit Server-Side Rendering oder mit reduzierter Datenauflösung anbieten, was natürlich mit einem größeren Entwicklungs- und Wartungsaufwand verbunden ist.
Client-Side Rendering ist zusammenfassend für Anwendungen geeignet, die sehr interaktiv sind aber nicht kritisch für Endnutzer_innen ohne State-of-the-Art Hardware sind. Client-seitige Anwendungen benötigen aufgrund der noch fehlenden Frameworks und Bibliotheken – gerade für die neue aber vielversprechende Grafik-API WebGPU – auch erhöhten Entwicklungsaufwand.
weBIGeo: Tiles + Client-Side Analysis & Rendering
weBIGeo setzt auf client-seitige Analyse und Rendering für maximale Flexibilität. Für das Rendering der Basiskarte verwendet es klassische Tiles (Flugaufnahmen und Höhendaten). Für unsere Demo-Anwendungen werden wir zusätzlich Punkt- und Rasterdaten einbinden, wobei die Rasterdaten auch als Tiles zur Verfügung stehen. Die Datenquellen werden dann zur Laufzeit miteinander verknüpft und als Overlay über der Karte dargestellt. Für unsere Zielgruppe (Datenwissenschafler_innen, Datenjournalist_innen, Open Source Community) bietet dies die beste Möglichkeit, Daten flexibel zu explorieren. Gleichzeitig können wir bei dieser Zielgruppe davon ausgehen, dass ihr relativ gute Endgeräte zur Verfügung stehen.
Zukunftsvision: Hybrides Datenmanagement
Wir mussten bei der Konzeption der Anwendungsszenarios feststellen, dass es für reine Client-seitige Datenanalyse in der Zukunft noch viel Konzeptions- und Implementierungsbedarf gibt, um die Datenflüsse adäquat zu managen damit wirklich flexibel Visualisierungen erstellt werden können. Um zu verhindern, dass das Herunterladen und Speichern von großen Daten zum Bottleneck wird, wäre es nötig, größere Daten in einer räumlichen Datenstruktur abzuspeichern um gezielt auch nur benötigte Teile der Daten herunterladen zu können. Um zu vermeiden, dass Daten oftmalig vom Server heruntergeladen werden, benötigt man intelligentes Caching. Um Wartezeiten zu minimieren, wenn viele Daten benötigt werden, könnte zusätzlich ein ausgeklügeltes Scheduling umgesetzt werden. Unsere ersten Compute Shader Experimente mit weBIGeo haben jedenfalls gezeigt, dass das Datenmanagement das Bottleneck ist, welches die anzuzeigenden Datenmengen sehr einschränkt.
Es würde sich also um ein neues hybrides Paradigma handeln, das vorberechnete Level-of-Detail Datenstrukturen (z.B., vorberechnete Overlay-Tiles von Rasterdaten oder räumlich unterteilte Punktdaten) zur Laufzeit progressiv in ein Multi-Level Overlay verknüpfen kann. weBIGeo bietet jedenfalls eine erste technische Basis um das Potential in Zukunft voll auszuschöpfen.








