Förderjahr 2023 / Projekt Call #18 / ProjektID: 6745 / Projekt: weBIGeo
weBIGeo zeigt, dass die Simulation und Visualisierung großer Datenmengen im Browser möglich ist. Am Beispiel einer Lawinensimulation erklären wir, wie eine solche Simulation funktioniert und wie sich die Berechnung in Echtzeit durchführen lässt.
Lawinenmodelle
Es gibt grundsätzlich zwei verschiedene Ansätze für die Simulation von Lawinen.
Physikalische Modelle versuchen die zugrundeliegenden physikalischen Gesetze möglichst genau nachzubilden. Typischerweise wird hier eine Lawine als große Menge einzelner Partikel verstanden, die jeweils physikalischen Kräften ausgesetzt sind. Durch die Wahl der richtigen Parameter wie Masse, Reibungskraft, usw. gleicht die Bewegung dieser Partikelmenge dem Verhalten einer Lawine. Solche Modelle sind in der Regel komplex und rechenintensiv, liefern aber sehr genaue Ergebnisse. Allerdings wird vorausgesetzt, dass verschiedenste physikalische Parameter bekannt sind, was sich in der Praxis manchmal als schwieriges Problem herausstellt.
Im Gegensatz dazu stützen sich datenbasierte, empirische Modelle auf vorhandene Daten zu Lawinenabgängen und leiten daraus Bewegungsregeln ab. Diese Regeln entsprechen nicht zwangsläufig physikalischen Gesetzen, enthalten aber meist ähnliche Konzepte. Beispielsweise ist das Miteinbeziehen der bisherigen Bewegungsrichtung ähnlich zum physikalischen Konzept Momentum. Empirische Modelle haben oft weniger Parameter als physikalische Modelle und sind nicht so rechenintensiv, liefern jedoch weniger genaue Ergebnisse (besonders im kleinen Maßstab). In größerem Maßstab sind diese Ungenauigkeiten meist vernachlässigbar.
Da uns Lawinen im Gebiet einer Skitour interessieren, betrachten wir einen Bereich von einigen Quadratkilometern. Aus diesem Grund haben wir uns für den empirischen Ansatz entschieden. Üblicherweise werden solche Modelle in zwei Komponenten, nach den zwei Fragen "Wohin fließt die Lawine?" und "Wie weit fließt die Lawine?", eingeteilt.
Wohin fließt die Lawine?
Lawinen fließen bekanntlich von oben nach unten. Aber oft gibt es mehrere Möglichkeiten bergab. Welchen Weg die Lawine durch das Terrain genau nimmt wird vom sogenannten Routing-Modell festgelegt. Dieses definiert Regeln für die Fließrichtung. In der Literatur wird unterschieden zwischen
-
Single flow direction- und
-
Multiple flow direction-Modellen.
Dabei geben Single flow direction-Modelle pro Schritt immer nur eine einzige Richtung an, in welche sich die Lawine weiterbewegt - wie beispielsweise die Richtung, in der das Gefälle am stärksten ist. Multi flow direction-Modelle können Lawinen pro Schritt aufteilen und in mehrere Richtungen gleichzeitig schicken, wie zum Beispiel in alle Richtungen, in die es bergab geht. In der Realität werden Lawinen durch das Mitreißen von Schneemaßen auf ihrem Weg breiter und formen dadurch sogenannte Lawinenkegel. Somit ist naheliegend, dass Multi flow direction-Modelle besser geeignet sind, um Lawinen darzustellen.
Sehen wir uns dazu ein Beispiel an. Wir werten ein (fiktionales) Multi direction flow-Modell auf einem Höhenmodell aus. In unserem Beispielmodell wird eine Lawine von der aktuellen Zelle in alle Nachbarzellen geleitet, deren Höhen geringer als die aktuelle Höhe sind.
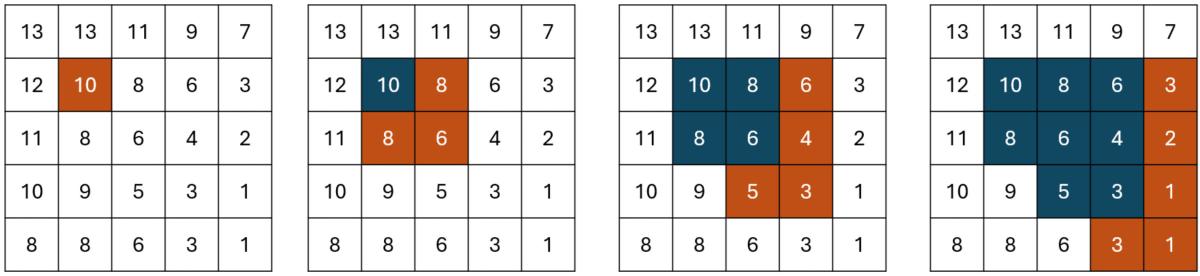
Die Zahlen repräsentieren die Höhen. Die Simulation beginnt in einer Zelle mit der Höhe 10. Alle acht Nachbarzellen werden überprüft und jene mit kleineren Höhen ausgewählt. Für alle ausgewählten Zellen muss anschließend wieder der Höhenvergleich mit den jeweiligen Nachbarzellen durchgeführt werden. Es ergeben sich also nach und nach mehr Zellen, für welche das Routing Modell ausgewertet werden muss. Aktuelle Modelle wie Flow-Py oder Flow-R funktionieren nach dem gleichen Prinzip, verwenden jedoch Regeln, die etwas komplexer sind als Höhenvergleiche.
Dieser Ablauf verhindert eine effiziente Parallelisierung, da in jedem Schritt mehr Arbeit hinzukommt, welche wieder neu aufteilt werden müsste. Das Neuverteilen der Arbeit pro Schritt wäre zwar technisch machbar, führt aber zu signifikantem Overhead (insbesondere, wenn die parallele Berechnung auf der GPU ausgeführt werden soll).
Wir bedienen uns daher einem kleinen Trick. Wir formulieren unser Modell als sogenannte Monte-Carlo-Methode. Monte-Carlo-Methoden sind Algorithmen, die durch wiederholtes, zufälliges Auswählen von Elementen (mit einer bestimmten Wahrscheinlichkeitsverteilung) sich dem korrekten Ergebnis annähern. Beispielsweise kann damit der Wert von Pi berechnet werden.
Dieses Prinzip können wir auf Routing Modelle umlegen. In jedem Schritt berechnen wir uns eine Hauptbewegungsrichtung. Diese Richtung hängt von der bisherigen Bewegungsrichtung sowie der Richtung des steilsten Gefälles an der aktuellen Position ab. Anschließend wählen wir zufällig eine Richtung, wobei Richtungen nahe der Hauptbewegungsrichtung wahrscheinlicher sind. Dann bewegen wir uns nur in genau diese eine Richtung. Bis hier ist das Modell daher ein Single flow direction-Modell. Wenn wir allerdings an unserem Lawinenstartpunkt ganz viele einzelne Pfade auf diese Art berechnen, bekommen wir schlussendlich ein Multi flow direction-Modell, welches Lawinenkegel darstellen kann. Alle diese Pfade sind unabhängig berechenbar und erfordern genau gleich viel Arbeit. Sie können daher effizient parallel auf der GPU berechnet werden.
Wie weit geht die Lawine?
Ein bloßes Routing Modell berechnet Lawinenpfade. Die Länge dieser Pfade hängt von der Anzahl der Simulationsschritte ab. Wird die Schrittzahl zu niedrig gewählt, sind die Lawinen zu kurz. Bei zu hoher Schrittzahl werden sie zu lang. Es werden deshalb zusätzliche Bedingungen benötigt, um festzustellen, bis wohin eine Lawine gehen soll. Diese Bedingungen werden Runout distance-Modell genannt. Die Schrittzahl wird so hoch gesetzt, dass Pfade mindestens so lang werden, wie reale Lawinen werden können, eventuell länger. Das Runout distance-Modell legt dann fest, wo diese möglicherweise zu langen Lawinenpfade enden sollen.
Dabei orientieren sich auch diese Modelle an Daten aus vergangenen Lawinenereignissen. Für unsere Simulation verwenden wir das Runout distance-Modell von Flow-Py. Es funktioniert so: Die Höhen werden entlang des Lawinenpfades betrachtet und in jedem Schritt der Winkel zum Startpunkt berechnet. Ist dieser Winkel kleiner als ein vorher festgelegter Winkel α, ist die Lawine zu Ende. Je größer der Winkel α, desto kürzer die Lawinen. Realistische Werte für die Alpen sind im Bereich von 20° bis 30°.
Und... Wo geht die Lawine eigentlich los?
Die Startpunkte von Lawinen werden als Auslösebereiche bezeichnet. In der Realität beeinflussen zahlreiche Faktoren, wo Lawinen tatsächlich ausgelöst werden können und wie hoch die Wahrscheinlichkeit dafür ist. Für unsere Betrachtungen beschränken wir uns jedoch ausschließlich auf die Steilheit des Geländes als einzigen Faktor. Der Großteil der Lawinenabgänge tritt bei einer Hangneigung zwischen 30° und 45° auf. Dieser Wert variiert je nach Lawinentyp, dient aber als Grundlage für unsere Analyse.
In weBIGeo betrachten wir daher alle Geländeabschnitte mit einer definierbaren Hangneigung (per Standard zwischen 30° und 45°) als potenzielle Auslösebereiche. Den Verlauf dort ausgelöster Lawinen simulieren wir auf Basis eines festen Rasters, dessen Auflösung die Nutzer_innen beliebig einstellen können.
Ausblick
Unser Modell ermöglicht, durch Parallelisierung mithilfe der GPU sehr schnell Ergebnisse zu berechnen. Dies wiederum erlaubt, die Simulationsparameter interaktiv anzupassen und so verschiedene Szenarien durchzuspielen.
Neugierig wie unsere Simulationen aussehen? Im nächsten Blogpost zeigen wir euch unsere visuellen Ergebnisse und erklären, wie Sie selbst Lawinensimulationen im Browser durchführen könnt!









